Создание сервис-воркера: разбор примера
Оригинал статьи: Making A Service Worker: A Case Study
Оглавление:- Так что же такое сервис-воркер?
- Базовая концепция сервис-воркера
- Регистрация, установка и активация сервис-воркера
- Путаница в консоли
- Чего мы добились
- Выборка с помощью сервис-воркеров
- Пишем обработчик выборки
- Содержимое HTML: реализация стратегии Network-First
- Остальные ресурсы: стратегия Cache-First
- Первая версия сервис-воркера готова
- Версионирование и обновление сервис-воркера
- Ключи для версионирования кэша
- Добавляем обработчик активации
- Заключение
Шума вокруг service worker API предостаточно, эта технология уже реализована в популярных браузерах. Есть книги, записи в блогах, образцы кода и инструменты. Но я хотела изучить новую концепцию тщательно, поэтому идеалом было с головой окунуться в новое и начать работу с нуля.
Все полученные таким образом шишки и синяки, встреченные глюки и баги дали свои результаты: теперь я разбираюсь в сервис-воркерах намного лучше и могу помочь вам избежать некоторых головных болей, с которыми я столкнулась, осваивая новый API.
Сервис-воркеры делают много разных вещей и есть тысячи способов использовать их возможности. Я решила создать простой сервис-воркер для своего несложного статического сайта, на базовом уровне реализовав возможности устаревшего Application Cache API, в частности, для возможности:
- функционирования сайта офлайн
- увеличения производительности путем уменьшения сетевых запросов для определенных ресурсов
Перед тем как начать, я хочу упомянуть двух людей, благодаря которым эта работа стала возможной. Это Джереми Кит, реализовавший сервис-воркеров на своем сайте ( и его реализация стала основой для моего кода). Я была вдохновлена постом, описывающим его опыт с сервис-воркером. Фактически, моя статья является производной от его текста, собственно, она написана как ответ на обращение из его записи:
Если вы решите поэкспериментировать с сервис-воркерами, пожалуйста расскажите о своем опыте.
Также огромная благодарность Джеку Арчибальду за его великолепный технический обзор и отзывы. Всегда радует, когда один из разработчиков спецификации сервис-воркеров может разъяснить сложные моменты.
Так что же такое сервис-воркер?
Сервис-воркер это скрипт, работающий между сайтом и сетью и дающий вам, кроме прочего, возможность перехватывать сетевые запросы и отвечать на них различными способами.
Чтобы ваш сайт или ваше приложение работали, браузер запрашивает необходимые ресурсы, такие как страницы HTML, JavaScript, изображения и шрифты. В прошлом управление всем этим было прерогативой браузера. Если у браузера не было доступа к сети, вы могли увидеть сообщение о работе в автономном режиме и недоступности ресурсов. Были техники, с помощью которых вы могли улучшить кэширование ресурсов, но последнее слово всегда оставалось за браузером.
Это был не самый приятный опыт для пользователей, оставшихся без доступа к сети и у веб-разработчиков тогда было немного возможностей по управлению кэшем браузера.
Несколько лет назад появились новые надежды с появлением Application Cache (или AppCache), ожидалось, что с его помощью можно будет диктовать браузеру, как обрабатывать различные ресурсы, это должно было помочь сайту или приложению работать в офлайне. Но за простым синтаксисом Yet AppCache скрывались отсутствие гибкости и изначально неудачная архитектура.
Сервис-воркеры относительно молоды и делают то, что делает AppCache, а также многое другое. Но на первый взгляд они кажутся непростыми. Спецификация написана абстрактно и тяжело, для работы используются множественные API: cache, fetch и т.д. При этом сервис-воркеры обладают большим функционалом — push-уведомления, а скоро и фоновая синхронизация. В сравнении с Application Cache это все выглядит сложным.
AppCache (который постепенно уходит) был достаточно легким в момент изучения и ужасным для всех последующих моментов, сервис-воркеры требуют больших усилий для первоначального освоения, но в то же время они мощнее и полезнее, а в случае каких-либо ошибок в коде не нанесут особого вреда.
Базовая концепция сервис-воркера
Сервис-воркер это файл с кодом JavaScript. Да, вы можете писать в нем тот самый JavaScript, который вы знаете и любите, учитывая при этом некоторые вещи.
Сервис-воркер выполняет скрипты в отдельном потоке браузера относительно страницы, которую он контролирует. Существуют способы сообщения между воркерами и страницами, но сами воркеры выполняются в изолированном пространстве имен. Это, например, означает, что у вас нет доступа к DOM этих страниц. Я представляю сервис-воркера как разновидность изолированной от страницы вкладки, это не совсем точная, но полезная метафора для начала понимания.
JavaScript в сервис-воркере должен быть неблокирующим. Для этого надо использовать асинхронный API. Например, вы не можете использовать localStorage в сервис-воркере (потому что это синхронный API). Смешно, но даже зная это, я пошла на риск нарушения этого правила, вы это еще увидите.
Регистрация сервис-воркера
Чтобы сервис-воркер заработал, его надо зарегистрировать. Регистрация делается вне сервис-воркера, другой страницей или скриптом вашего сайта. На моем сайте есть глобальный скрипт site.js, который подключен на каждой странице, именно в этом скрипте регистрируется сервис-воркер.
Когда вы регистрируете сервис-воркер, вы опционально можете указать ему область действия. Вы можете дать сервис-воркеру инструкцию обрабатывать только часть сайта (например, /blog/) или весь сайт (/).
События и жизненный цикл сервис-воркера
Основная часть работы сервис-воркера заключается в прослушивании соответствующих событий и полезном реагировании на них. Различные события запускаются в разные моменты жизненного цикла сервис-воркера.
Как только сервис-воркер зарегистрирован и скачан, происходит его фоновая установка. Ваш сервис-воркер может прослушивать событие install и выполнять задачи, соответствующие этой стадии.
В нашем случае мы хотим использовать возможности состояния install для предварительного кэширования ресурсов, которые позднее нам точно понадобятся в офлайне.
После окончания стадии install происходит активация сервис-воркера. Это значит, что сервис-воркер уже контролирует свою зону деятельности и может выполнять свои задачи. Событие activate не слишком интригующе для нового сервис-воркера, но мы увидим, как оно полезно при обновлении версии сервис-воркера.
Время события активации у нового сервис-воркера и обновляемой версии существующего сервис-воркера различается. Если в браузере не зарегистрирована предыдущая версия данного сервис-воркера, активация происходит немедленно после окончания установки.
Как только установка и активация завершены, они больше не будут вызываться до момента скачивания и регистрации новой версии сервис-воркера.
Помимо установки и активации нас в первую очередь интересует событие fetch, именно оно позволит сделать наш сервис-воркер полезным. Кроме него, есть еще несколько полезных событий, например, события синхронизации и уведомлений.
Если вы заинтересовались этой темой, вам стоит почитать об интерфейсах, реализуемых сервис-воркерами. Именно за счет имплементации интерфейсов сервис-воркеры получают основную массу своих событий и большую часть своей функциональности.
Основанный на промисах API сервис-воркера
API сервис-воркера широко использует промисы. Промис представляет конечный результат асинхронной операции, даже если настоящее значение не будет известно до времени завершения этой операции в будущем.
getAnAnswerToADifficultQuestionSomewhereFarAway()
.then(answer => {
console.log('I got the ${answer}!');
})
.catch(reason => {
console.log('I tried to figure it out but couldn't because ${reason}');
});
Функция getAnAnswer… возвращает Promise, который (как мы надеемся) со временем будет выполнен и вернет нам ответ. Затем этот ответ может передаваться любому присоединенному к цепи обработчику функции или (в случае неудачи) Promise вернет нам ошибку, которой займется обработчик catch.
О промисах можно много рассказать, но я постараюсь ограничиться простыми примерами (или хотя бы прокомментированными). Я советую вам ознакомиться с промисами подробнее, если вы новичок.
Примечание: в коде сервис-воркера использованы отдельные возможности ECMAScript6 (или ES2015), так как поддерживающие сервис-воркеров, поддерживают и эти возможности. Конкретно в примере использованы стрелочные функции и строки шаблонов.
Дополнительные требования сервис-воркеров
Также важно отметить, что для работы сервис-воркеров необходим HTTPS. С одним важным и полезным исключением: чтобы лишний раз не издеваться над разработчиками, на localhost сервис-воркеры работают с простым http.
Забавный факт: этот проект заставил меня сделать то, что я долго откладывала: получить SSL-сертификат и настроить SSL для поддомена www на своем сайте. Это то, к чему я призываю и вас, так как многие новые технологии в будущем будут требовать SSL.
Все примеры из статьи на данный момент работают в Chrome, Opera и Firefox начиная с версии 44. Подробнее о поддержке сервис-воркеров в браузерах можно узнать на страничке Джейка Арчибальда Is Service Worker Ready?
Регистрация, установка и активация сервис-воркера
После ознакомления с теорией мы можем начать работу над нашим сервис-воркером.
Для установки и активации сервис-воркера мы будем прослушивать события install и activate и воздействовать на них.
Мы можем начать с пустого файла с нашим сервис-воркером и добавить в него пару обработчиков событий. В serviceWorker.js:
self.addEventListener('install', event => {
// Do install stuff
});
self.addEventListener('activate', event => {
// Do activate stuff: This will come later on.
});
Регистрация сервис-воркера
Теперь нам надо сказать страницам сайта, чтобы они использовали сервис-воркер.
Запомните, регистрация происходит вне сервис-воркера — в моем случае на каждой странице сайта для этого подключается скрипт /js/site.js.
Вот его содержимое:
if ('serviceWorker' in navigator) {
navigator.serviceWorker.register('/serviceWorker.js', {
scope: '/'
});
}
Предварительное кэширование статических ресурсов при установке
Я хочу использовать стадию установки для предварительного кэширования отдельных ресурсов моего сайта.
- предварительно кэшируя некоторые статические ресурсы (изображения, CSS, JavaScript), которые используются на многих страницах сайта, я могу ускорить время загрузки, вытягивая их из кэша, вместо того, чтобы качать их из сети при последующих загрузках страницы.
- предварительно кэшируя автономную запасную страницу, я могу показать красивую страницу в случаях, когда я не могу выполнить запрос страницы, когда пользователь в офлайне.
Для этого необходимы следующие шаги:
- Прикажите событию
installне завершаться, пока вы не выполните то, что вы хотите с помощьюevent.waitUntil. - Откройте соответствующий кэш и закачайте в него статические ресурсы, используя
Cache.addAll. В терминологии прогрессивных веб-приложений эти ресурсы будут “оболочкой приложения”.
Расширим обработчик install в /serviceWorker.js:
self.addEventListener('install', event => {
function onInstall () {
return caches.open('static')
.then(cache => cache.addAll([
'/images/lyza.gif',
'/js/site.js',
'/css/styles.css',
'/offline/',
'/'
])
);
}
event.waitUntil(onInstall(event));
});
Сервис-воркер реализует интерфейс CacheStorage, делающий свойство caches доступным глобально в нашем сервис-воркере. В caches есть несколько полезных методов, например, open и delete.
Вы можете видеть здесь работу промисов: caches.open возвращает Promise, занимающийся объектом cache после успешного отрытия статического кэша (static), addAll также возвращает промис, контролирующий сохранение всех переданных ресурсов в кэше.
Я говорю event подождать, пока Promise, возвращаемый моей функцией-обработчиком разрешится успешно. Теперь мы можем быть уверены, что все предварительно кэшируемые элементы рассортируются до завершения установки.
Путаница в консоли
Устаревшие логи
Это не баг, а скорее недоразумение: если вы используете в сервис-воркерах console.log, Chrome будет выводить эти сообщения (а не удалять) при всех следующих запросах страниц. Это может создать впечатление, что события происходят многократно, а код выполняется снова и снова.
Например, добавим log к нашему обработчику install:
self.addEventListener('install', event => {
// … as before
console.log('installing');
});

В Chrome 47 сообщение об установке будет появляться в логах на всех последующих запросах страницы. На самом деле событие install не выполняется при каждой загрузке страницы, это выводятся устаревшие логи. (увеличенная версия)
{kind=link}
Мнимая ошибка
Другая странность заключается в том, что сразу после установки и активации сервис-воркера, последующие загрузки всех страниц с ним вызывают ошибку в консоли. (Баг пофиксен 18 февраля 2016 г.).

В Chrome 47 доступ к странице с зарегистрированным сервис-воркером вызывает ошибку в консоли. (увеличенная версия)
{kind=link}
Чего мы добились
Сервис-воркер обрабатывает событие install и предварительно кэширует некоторые статические ресурсы. Если вы использовали и зарегистрировали его, он сможет закэшировать ресурсы, но пока еще не сможет использовать их в офлайне.
Содержимое serviceWorker.js выложено на GitHub.
Выборка с помощью сервис-воркеров
До сих пор у нашего сервис-воркера был обработчик install и ничего больше. Магия нашего сервис-воркера начинается, когда запускаются события fetch.
Мы можем реагировать на событие выборки разными способами. Используя различные сетевые стратегии, мы можем приказать браузеру всегда загружать определенные ресурсы из сети (обеспечивая тем самым свежесть контента), предпочитая при этом кэшированные копии статических ресурсов — это позволит облегчить загружаемые страницы. Мы также можем сделать запасной вариант для офлайна, если попытки загрузки потерпят неудачу.
Всякий раз, когда браузер хочет загрузить ресурс, находящийся в зоне действия сервис-воркера, мы можем узнать об этом добавив обработчик eventListener в serviceWorker.js:
self.addEventListener('fetch', event => {
// … Perhaps respond to this fetch in a useful way?
});
Каждая неудачная попытка загрузка в зоне деятельности сервис-воркера будет запускать это событие — страницы HTML, CSS, скрипты, изображения и т.д. Мы можем выборочно обрабатывать реакцию браузера на все события выборки.
Должны ли мы обрабатывать выборку?
Когда происходит событие fetch для ресурса, первое, с чем надо определиться это должен ли сервис-воркер прерывать загрузку данного ресурса. В ином случае сервис-воркер не будет ничего делать и позволит браузеру работать по умолчанию.
В итоге мы оказываемся со следующей базовой логикой в файле serviceWorker.js:
self.addEventListener('fetch', event => {
function shouldHandleFetch (event, opts) {
// Should we handle this fetch?
}
function onFetch (event, opts) {
// … TBD: Respond to the fetch
}
if (shouldHandleFetch(event, config)) {
onFetch(event, config);
}
});
Функция shouldHandleFetch оценивает данный запрос и определяет, будет ли этим заниматься сервис-воркер, или пусть браузер совершает свои дефолтные действия.
Почему бы не использовать промисы?
Сохраняя общую привязанность сервис-воркера к промисам, в первой версии кода обработчик события fetch выглядел так:
self.addEventListener('fetch', event => {
function shouldHandleFetch (event, opts) { }
function onFetch (event, opts) { }
shouldHandleFetch(event, config)
.then(onFetch(event, config))
.catch(…);
});
Вроде бы логично, но я сделала пару ошибок, типичных для новичка в промисах. Я клянусь, что я не видела проблем с кодом, это Джейк указал мне на ошибки. (Урок на будущее: как всегда, если код кажется плохим, то, скорее всего, он плохой).
Ошибки (rejected) в промисах не должны использоваться для индикации типа “У меня есть ответ, который мне не нравится”. Вместо этого они должны показывать: “Кажется, что-то пошло не так при попытке получить ответ”. Именно, ошибки должны быть исключениями.
Критерии валидных запросов
Итак, давайте продолжим определять, применим ли текущий запрос на загрузку ресурса для нашего сервис-воркера. Для моего сайта критерии следующие:
- Запрошенный URL должен представлять нечто, что я хочу закэшировать или ответить иным образом. Путь к нему должен соответствовать регулярному выражению валидного пути.
- Метод HTTP-запроса должен быть
GET. - Запрашиваемый ресурс должен находиться на моем домене (
lyza.com).
Если какой-либо из тестов criteria возвращает false, мы не будем обрабатывать запрос. Код serviceWorker.js:
function shouldHandleFetch (event, opts) {
var request = event.request;
var url = new URL(request.url);
var criteria = {
matchesPathPattern: !!(opts.cachePathPattern.exec(url.pathname),
isGETRequest : request.method === 'GET',
isFromMyOrigin : url.origin === self.location.origin
};
// Create a new array with just the keys from criteria that have
// failing (i.e. false) values.
var failingCriteria = Object.keys(criteria)
.filter(criteriaKey => !criteria[criteriaKey]);
// If that failing array has any length, one or more tests failed.
return !failingCriteria.length;
}
Конечно, критерии здесь именно для моего сайта и на других сайтах они будут отличаться. event.request это объект Request в котором содержатся все виды данных, на которые вы можете взглянуть, чтобы определиться с желаемым поведением обработчика.
Тривиальное замечание: если вы заметили вторжение config, передаваемого как аргумент opts в функцию обработчика, то можете взять с полки пирожок. Я учла некоторые многократно используемые значения и специально создала объект config на высшем уровне пространства сервис-воркера:
var config = {
staticCacheItems: [
'/images/lyza.gif',
'/css/styles.css',
'/js/site.js',
'/offline/',
'/'
],
cachePathPattern: /^\/(?:(20[0-9]{2}|about|blog|css|images|js)\/(.+)?)?$/
};
Почему белый список?
Вы должно быть удивитесь, почему я кэширую только те ресурсы, путь к которым соответствует регулярному выражению:
/^\/(?:(20[0-9]{2}|about|blog|css|images|js)\/(.+)?)?$/
…вместо кэширования всего, что приходит с моего домена? Пара причин:
- Я не хочу кэшировать сам сервис-воркер.
- Когда я занимаюсь разработкой сайта локально, генерируются некоторые запросы для вещей, которые я не хочу кэшировать. Например, я использую
browserSync, который делает кучу запросов при разработке. Я не хочу кэшировать все это! Слишком долго и муторно вспоминать все, что я не хочу кэшировать (и тем более прописывать все это в конфигурации сервис-воркера). Поэтому решение с белым списком будет более естественным.
Пишем обработчик выборки
Теперь мы готовы к тому, чтобы передать применимые запросы на загрузку обработчику. В функции onFetch надо определить следующее:
- какой тип ресурсов запрашивается,
- и как выполнить этот запрос.
1. Определение типа запрашиваемого ресурса
Я могу посмотреть на заголовок HTTP Accept, чтобы получить подсказку о запрошенном типе ресурсов. Это помогает мне определиться с тем, как я хочу обработать запрос.
function onFetch (event, opts) {
var request = event.request;
var acceptHeader = request.headers.get('Accept');
var resourceType = 'static';
var cacheKey;
if (acceptHeader.indexOf('text/html') !== -1) {
resourceType = 'content';
} else if (acceptHeader.indexOf('image') !== -1) {
resourceType = 'image';
}
// {String} [static|image|content]
cacheKey = resourceType;
// … now do something
}
Чтобы все было упорядоченным, я хочу размещать разные типы ресурсов в разные кэши, это позволит в последствии управлять ими. В данном кэше ключ String выбран мной произвольно — вы можете называть свой кэш как угодно, у cache API нет на этот счет предрассудков.
2. Ответ на выборку
Следующее, что нужно сделать onFetch это ответить на событие fetch.
function onFetch (event, opts) {
// 1. Determine what kind of asset this is… (above).
if (resourceType === 'content') {
// Use a network-first strategy.
event.respondWith(
fetch(request)
.then(response => addToCache(cacheKey, request, response))
.catch(() => fetchFromCache(event))
.catch(() => offlineResponse(opts))
);
} else {
// Use a cache-first strategy.
event.respondWith(
fetchFromCache(event)
.catch(() => fetch(request))
.then(response => addToCache(cacheKey, request, response))
.catch(() => offlineResponse(resourceType, opts))
);
}
}
3. Осторожнее с асинхронностью!
В нашем случае shouldHandleFetch не делает ничего асинхронного, также как и onFetch до точки event.respondWith. Если что-то асинхронное происходит до этого, у нас возникнут проблемы. event.respondWith должен вызываться с момента события fetch и до возврата контроля в браузер. То же относится и к event.waitUntil. В принципе, если вы обрабатываете событие, то делайте что-либо немедленно (синхронно) или прикажите браузеру продержаться пока ваши асинхронные задачи не будут выполнены.
Содержимое HTML: реализация стратегии Network-First
Ответы на запросы fetch подразумевают внедрение соответствующей сетевой стратегии. Рассмотрим внимательно способ наших ответов на запросы контента HTML (resourceType === 'content').
if (resourceType === 'content') {
// Respond with a network-first strategy.
event.respondWith(
fetch(request)
.then(response => addToCache(cacheKey, request, response))
.catch(() => fetchFromCache(event))
.catch(() => offlineResponse(opts))
);
}
Способ, с помощью которого мы выполняем запросы для контента называется стратегия Network-First (сначала — сеть). Так как содержимое HTML это самая важная часть моего сайта и он часто меняется, я всегда стараюсь получать свежие версии HTML-документов из сети.
Разберем это пошагово.
1. Пытаемся скачать ресурс из сети
fetch(request)
.then(response => addToCache(cacheKey, request, response))
Если сетевой запрос удался (т.е. промис разрешился), идем дальше и помещаем копию документа HTML в соответствующий кэш (content). Это называется кэширование read-through.
function addToCache (cacheKey, request, response) {
if (response.ok) {
var copy = response.clone();
caches.open(cacheKey).then( cache => {
cache.put(request, copy);
});
return response;
}
}
Ответы могут использоваться только один раз.
С полученным ответом нам надо сделать две вещи:
- закэшировать его
- ответить на событие с ним (т.е. вернуть его)
Так как объекты Response могут использоваться лишь один раз, клонирование позволяет создать копию для нужд кэша:
var copy = response.clone();
Не кэшируйте плохие ответы. Не повторяйте мою ошибку, в первой версии моего кода не было этого условия:
if (response.ok)
Будет неприятно закончить с закэшированной ошибкой 404 и прочими неудачными ответами в кэше. Кэшируйте только удачные ответы.
2. Пытаемся извлечь кэш
Если ресурс извлечен из сети успешно, дело сделано. Однако, если это не получилось, мы можем быть в автономном или ином компромиссном режиме. Попытаемся извлечь предыдущую копию HTML из кэша:
fetch(request)
.then(response => addToCache(cacheKey, request, response))
.catch(() => fetchFromCache(event))
Вот функция fetchFromCache:
function fetchFromCache (event) {
return caches.match(event.request).then(response => {
if (!response) {
// A synchronous error that will kick off the catch handler
throw Error('${event.request.url} not found in cache');
}
return response;
});
}
Примечание: не надо указывать, какой кэш вы хотите проверить с помощью caches.match, проверяйте все сразу.
3. Делаем запасной вариант для офлайна
Если мы все сделали, но у нас нет ничего в кэше, нам желательно подготовить запасной вариант. Для HTML это может быть страница ` /offline/`. Это страница сообщает пользователю, что он в офлайне и его запрос не может быть выполнен сейчас, своего рода аналог страницы 404.
fetch(request)
.then(response => addToCache(cacheKey, request, response))
.catch(() => fetchFromCache(event))
.catch(() => offlineResponse(opts))
Функция offlineResponse:
function offlineResponse (resourceType, opts) {
if (resourceType === 'image') {
return new Response(opts.offlineImage,
{ headers: { 'Content-Type': 'image/svg+xml' } }
);
} else if (resourceType === 'content') {
return caches.match(opts.offlinePage);
}
return undefined;
}
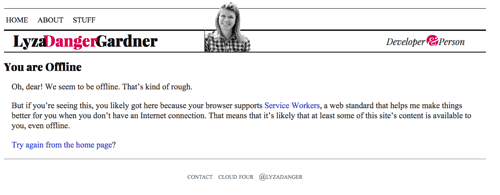
Страница офлайн (увеличенная версия)
{kind=link}
Остальные ресурсы: стратегия Cache-First
Логика загрузки остальных ресурсов (не HTML) использует стратегию Cache-First (т.е. сначала извлекаются ресурсы из кэша). Изображения и прочее статическое содержимое редко меняется на сайте, таким образом, запросив в начале кэш мы избегаем лишнего сетевого обмена.
event.respondWith(
fetchFromCache(event)
.catch(() => fetch(request))
.then(response => addToCache(cacheKey, request, response))
.catch(() => offlineResponse(resourceType, opts))
);
Этот подход включает следующие шаги:
- пытаемся извлечь ресурс из кэша
- в случае неудачи, извлекаем его из сети (кэшируя на ходу)
- в случае очередного фэйла используем офлайновый запасной вариант
Изображения офлайн
Мы можем вернуть изображение SVG с текстом “офлайн” в качестве запасного варианта, дополнив функцию offlineResource:
function offlineResponse (resourceType, opts) {
if (resourceType === 'image') {
// … return an offline image
} else if (resourceType === 'content') {
return caches.match('/offline/');
}
return undefined;
}
И внесем соответствующие изменения в config:
var config = {
// …
offlineImage: '<svg role="img" aria-labelledby="offline-title"'
+ 'viewBox="0 0 400 300" xmlns="http://www.w3.org/2000/svg">'
+ '<title id="offline-title">Offline</title>'
+ '<g fill="none" fill-rule="evenodd"><path fill=>"#D8D8D8" d="M0 0h400v300H0z"/>'
+ '<text fill="#9B9B9B" font-family="Times New Roman,Times,serif" font-size="72" font-weight="bold">'
+ '<tspan x="93" y="172">offline</tspan></text></g></svg>',
offlinePage: '/offline/'
};
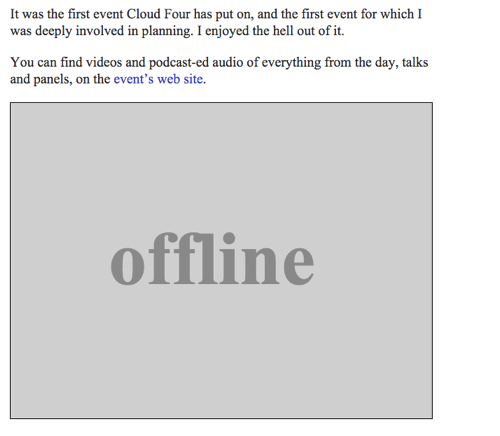
Изображение-заглушка для офлайна, исходники SVG — Jeremy Keith. (увеличенная версия)
{kind=link}
Остерегайтесь CDN
Остерегайтесь CDN, если вы ограничиваете загрузку только своим доменом. При создании первого сервис-воркера, я забыла, что мой провайдер хостинга отправляет часть ресурсов (изображения и скрипты) на свой CDN и поэтому они закачиваются не с моего сайта (lyza.com). Увы, это не работает. Мне пришлось отключить CDN для этих ресурсов (разумеется, не забывая про их оптимизацию).
Первая версия сервис-воркера готова
Первая версия нашего сервис-воркера готова. У нас есть обработчик install и открытый обработчикfetch, способный отвечать на запросы о загрузке, а также предоставлять кэшированные ресурсы и страницу-заглушку для автономного режима.
По мере серфинга пользователя по сайту, мы кэшируем все больше ресурсов. При переходе в автономный режим, они могут продолжить серфинг, если ресурс уже закэширован или увидят страницу-заглушку, если нужный ресурс отсутствует в кэше.
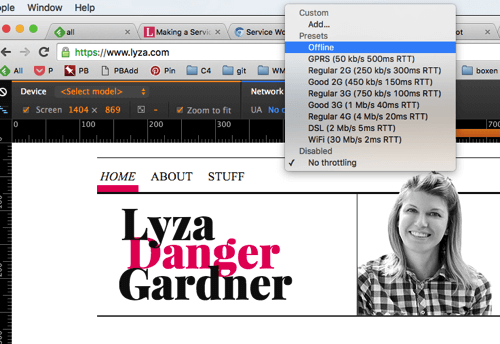
В Chrome вы можете тестировать поведение сервис-воркера в офлайне, выбрав в меню device mod презет Offline. Это бесценный трюк. (увеличенная версия)
{kind=link}
Полный код с обработкой загрузки (serviceWorker.js) выложен на GitHub.
Версионирование и обновление сервис-воркера
Если на нашем сайте больше никогда ничего не поменяется, то мы можем сказать, что все сделано. Однако иногда сервис-воркеры нуждаются в обновлении. Возможно, я захочу добавить кэширование к другим раздела сайта. Может, захочу расширить запасной вариант для офлайна. А может, в моем сервис-воркере найдется баг, который надо будет исправить.
Я хочу подчеркнуть, что существуют автоматические инструменты, чтобы сделать сервис-воркера частью вашего рабочего процесса, типа разработки Google Service Worker Precache. Нет необходимости заниматься версионированием вручную. Однако мой сайт достаточно прост для ручного версионирования изменений сервис-воркера. Он состоит из:
- простой строки для индикации версии
- имплементации в обработчике
activateочистки старых версий - обновлении обработчика
install, чтобы обновленные сервис-воркеры активировались быстрее
Ключи для версионирования кэша
Я могу добавить свойство version в объект config:
version: 'aether'
Эта строка должна меняться каждый раз, когда я хочу выпустить новую версию сервис-воркера. Я для именования использую имена греческих богов и героев, мне это нравится больше, чем использовать случайный набор строк или цифр.
Примечание: я внесла несколько изменений в код, добавив функцию (cacheName), генерирующую ключи кэша с префиксами. Она не относится к теме статьи, поэтому я не буду разбирать ее код, вы можете увидеть его в итоговом варианте сервис-воркера.
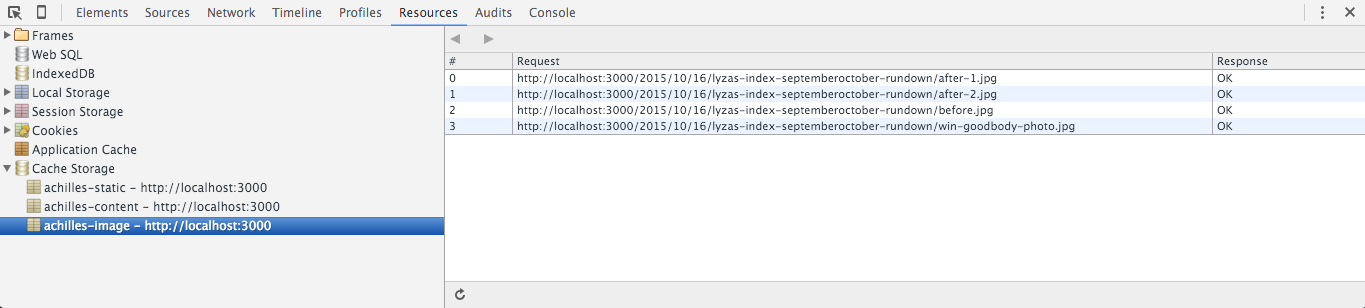
В Chrome вы можете видеть содержимое кэша во вкладке “Resources”. Вы можете видеть, что у разных версий моего сервис-воркера разные названия кэша. (в примере версия “Ахилл”). (увеличенное изображение)
{kind=link}
Не переименовывайте сервис-воркер
В один момент, я переименовала файл сервис-воркера, экспериментируя с системами именования. Не делайте так. Браузер зарегистрирует новый сервис-воркер, но старый останется установленным. И у вас будет бардак. Я уверена, что это можно обойти, но проще будет просто не переименовывать сервис-воркер.
Не используйте importScripts в конфигурации
Я пробовала поместить свой объект config во внешний файл и использовать self.importScripts() в сервис-воркере для его подключения. Это казалось разумным способом управления конфигурацией вне сервис-воркера, но здесь скрывался подвох.
Браузер побайтно сравнивает файлы сервис-воркера, чтобы определить, когда они обновились — так он узнает о необходимости запустить цикл загрузки и установки сервис-воркера. Изменения внешнего файла с конфигурацией не будут замечены сервис-воркером, а значит изменения конфигурации не будут приводить к обновлению сервис-воркера.
Добавляем обработчик активации
Цель в создании зависимых от версии имен кэша состоит в том, что мы очищаем кэш предыдущих версий. Если с момента активации остался кэш без префикса текущей версии, мы знаем, что он будет удален по причине ненужности.
Очищаем старый кэш
Для очистки старого кэша мы можем использовать следующую функцию:
function onActivate (event, opts) {
return caches.keys()
.then(cacheKeys => {
var oldCacheKeys = cacheKeys.filter(key =>
key.indexOf(opts.version) !== 0
);
var deletePromises = oldCacheKeys.map(oldKey => caches.delete(oldKey));
return Promise.all(deletePromises);
});
}
Ускоряем установку и активацию
Обновленный сервис-воркер будет скачан и установлен в фоновом режиме. Сейчас он находится в ожидании. По умолчанию, обновленный сервис-воркер не активируется, пока загружаются страницы, использующие старый сервис-воркер. Однако, мы можем ускорить этот процесс, внеся небольшие изменения в обработчик install:
self.addEventListener('install', event => {
// … as before
event.waitUntil(
onInstall(event, config)
.then( () => self.skipWaiting() )
);
});
skipWaiting вызовет activate немедленно.
Теперь завершим работу над обработчиком activate:
self.addEventListener('activate', event => {
function onActivate (event, opts) {
// … as above
}
event.waitUntil(
onActivate(event, config)
.then( () => self.clients.claim() )
);
});
Вызов self.clients.claim включит сервис-воркер немедленно на всех страницах в его зоне действия.

Вы можете использовать специальный URL chrome://serviceworker-internals в Chrome, чтобы видеть все зарегистрированные сервис-воркеры. (увеличенная версия)
{kind=link}
Это мой сайт в режиме Offline Network в Chrome, эмулирующий то, что увидит пользователь находясь в офлайне. Работает! (увеличенная версия)
{kind=link}
Заключение
Теперь у нас есть сервис-воркер с управлением версиями! Итоговый код serviceWorker.js выложен на GitHub.