Техническое SEO 2015: адаптируем сайт к органическому поиску
Оригинал статьи: Technical SEO 2015: Wiring Websites for Organic Search
Оглавление:- Доступность для сканирования
- Эффективное сканирование и индексация
- Поддержка ссылочного профиля
- Вершина айсберга
Спросите у 10 людей, что такое SEO и вы, скорее всего, услышите 10 разных ответов. Учитывая сомнительное прошлое индустрии это не удивляет. Злоупотребление ключевыми словами, дорвеи и спам в комментариях создали сео-оптимизаторам их репутацию в веб-сообществе. Разнообразные мошенники от SEO продолжают продвигать владельцам сайтов эти вредные методы, укрепляя миф о том, что оптимизация вашего сайта для Google или Bing это совершенно глупое занятие.
Излишне говорить, что это неправда.
Если говорить в широком смысле, то нынешняя индустрия поисковой оптимизации разделена на две связанные вещи: маркетинг контента и техническая оптимизация. Возможность создавать контент, вызывающий интерес у аудитории и создавать идентичность бренда важна для успеха любого сайта и в Интернете можно с легкостью найти статьи, описывающие это.
Вторая часть — техническая оптимизация часто скрыта за различной дезинформацией. Эта чрезвычайно богатая дисциплина является ключом для реализации потенциала органического поиска вашего контента и, несмотря на ее частое указание в резюме многих веб-разработчиков, она остается одной из неправильно понимаемых областей веб-разработки.
Сегодня мы рассмотрим некоторые фундаментальные принципы технического SEO, включая эффективность сканирования, контроль индексации, поддержка профиля ссылок и т.д. Это даст вам все богатство техник оптимизации органического поиска, применимых к большинству веб-сайтов. Приступим.
Доступность для сканирования
Поисковые системы используют ботов, называемых “spider” или “поисковый робот” для нахождения и индексирования содержимого в вебе. Поисковый робот Google (‘Googlebot’) обнаруживает URL, следуя по ссылкам и считывая карты сайтов, предоставленные веб-мастерами. Он интерпретирует контент, добавляет страницы к индексу Google и ранжирует их для поисковых запросов по степени релевантности.
Если Googlebot не сможет эффективно просканировать ваш сайт, то у вас будут проблемы с органическим поиском. Независимо от размера сайта, его истории и популярности, проблемы с индексированием уменьшают его возможности для его органического ранжирования. У Google есть так называемый “бюджет сканирования”, для каждого домена, что отражается в регулярности и глубине проходов Googlebot. Следовательно, наша основная цель это максимизация эффективности визитов Googlebot.
Архитектура и карты сайтов
Этот процесс начинается с создания архитектуры сайта. Не стоит обращать внимание на избитые советы о доступности всей информации в три клика; вместо этого надо сосредочиться на создании сайта в соответствии с лучшими практиками информационной архитектуры. Стоит прочесть книгу Питера Морвиля “Информационная архитектура интернета” (в сентябре 2015 вышло четвертое издание), также неплохое введение в базовые принципы информационной архитектуры , связанные с SEO, можно найти на Moz.com.
Структура сайта должна разрабатываться после обширных исследований ключевых слов, используемых пользователями при поиске. Это само по себе искусство и мы не будем сейчас раскрывать эту тему; в качестве общего правила надо ориентироваться на создание логичной и примерно симметричной пирамидальной иерархии со страницами основных категорий сверху и более специфичными страницами снизу. Глубину кликов надо учитывать, но это не должно быть вашей основной заботой.
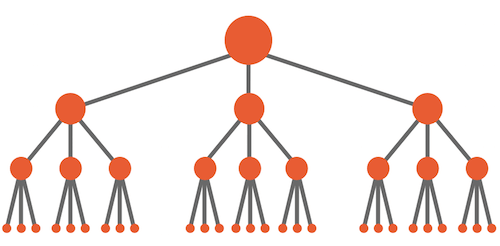
Диаграмма идеальной архитектуры сайта, верхняя точка — домашняя страница. (увеличенная версия)
{kind=link}
Эта архитектура должна выражаться в статичной и человекочитаемой структуре URL, свободной по возможности от динамических параметров и использующей для разделения слов дефисы, а не подчеркивания (это описано в рекомендациях Google по структуре URL). Поддерживайте последовательность при создании внутренних ссылок и избегайте создания не связанных с другими “брошенных” страниц. Помните, что поисковые роботы не могут использовать поисковые формы, все содержимое должно быть доступно по прямым ссылкам.
Поисковые движки могут узнать о структуре и содержании сайта с помощью карт сайта в формате XML (sitemap.xml, далее — карта сайта). Они особенно полезны для больших сайтов и сайтов со значительным количество мультимедийного содержимого, так как могут использоваться для указания типов контента, изменения частоты и приоритета страниц для поисковых роботов. Но надо учитывать, что карта сайта не решит фундаментальные архитектурные проблемы вроде покинутых страниц. Подробнее об использовании карты сайта вы можете узнать в документации Google.
Ваша карта сайта (это может быть и несколько карт сайта при разбитии одного файла для больших сайтов) может быть передана в Google с помощью поисковой консоли (Search Console, ранее — инструменты веб-мастера). Также имеет смысл добавить ссылку на карту сайта в robots.txt (текстовый файл, располагаемый обычно в корневом каталоге), чтобы сделать ее доступной для остальных поисковых роботов. Это делается с помощью следующей декларации:
Sitemap: http://yourdomain.com/sitemap-index-file.xml
Карту сайта можно сгенерировать автоматически, для этого есть большой выбор бесплатных сервисов, типа Yoast SEO Plugin для сайтов, работающих на WordPress (документация). Если вы создаете карту сайта вручную, обязательно следите за ее своевременностью. Не направляйте поисковых роботов на страницы, блокированные в вашем файле robots.txt, возвращающие ошибку 404, неканонические или на результат редиректов — все это приводит к пустой трате бюджета сканирования вашего сайта.
Мы глубже рассмотрим эти принципы, а также способы диагностики и устранения проблем в следующем разделе статьи.
Заблокированный контент
Иногда вам бывает нужно скрыть определенные страницы от поисковых систем. Обычно это области пользовательского доступа, персонализированные сайты, не ориентированные на большую аудиторию и сайты, находящиеся в стадии разработки. Наша цель здесь двоякая: мы предотвращаем появление этих URL в поисковой выдаче и не тратим в пустую бюджет сканирования сайта.
Мета теги для роботов это часть протокола исключения роботов (Robots Exclusion Protocol — REP), они могут использоваться для сообщения поисковым системам об исключении указанных URL из результатов поиска. Они размещаются внутри тега head, их синтаксис очень прост:
<meta name="robots" content="noindex,nofollow">
Тег принимает десятки значений, наиболее поддерживаемые из них это noindex и nofollow. Вместе они предотвращают индексирование страницы или переход робота по любой из ссылок на ней. Эти директивы могут быть заданы также в HTTP-заголовке, называемом X-Robots-Tag; это часто бывает более практичным при развертывании, особенно на больших сайтах. Например, в Apache с активированной директивой mod_headers следующий код предотвратит поисковое индексирование всех файлов PDF и переход по имеющимся в них ссылкам:
<FilesMatch ".pdf$">
Header set X-Robots-Tag "noindex, nofollow"
</FilesMatch>
И, наконец, robots.txt. Вопреки распространенному мнению, этот файл не не содержит средств предотвращения появления URL в результатах поиска также как и средств повышения безопасности и защиты личных данных. Это файл публично доступен и запрещает поисковым роботам индексировать содержимое определенных страниц или разделов сайта. Каждый поддомен в корневом домене может использовать отдельный файл robots.txt.
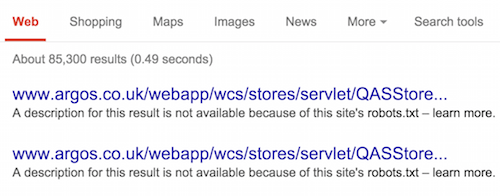
Как видите, блокированные в robots.txt страницы доступны в поисковой выдаче. (увеличенная версия)
{kind=link}
Базовый файл robots.txt определяет пользовательских агентов (поисковых роботов) и задает для них одно или несколько правил Disallow, это относительные URL, которые вы хотите заблокировать для поисковых роботов. Исключения задаются в следующих за ними правилах Allow. Использование паттернов для задания URL позволяет создавать более сложные правила, благодаря поддержке в Google и Bing двух регулярных выражений: окончания строки($) и универсального селектора (*). Вот простой образец:
User-agent: *
Disallow: /blocked-directory/
Allow: /blocked-directory/allowed-file.pdf$
У Google есть подробные рекомендации по написанию правил для robots.txt и есть инструменты для их тестирования в Search Console.
Отметьте, что добавление на страницу, заблокированную в robots.txt директивы noindex не предотвращает ее появление в результатах поиска. Поисковые роботы, учитывают директиву Disallow и не индексируют содержимое страницы, то есть не могут видеть этот тег. Вам надо разблокировать страницу и передать директиву noindex через HTTP-заголовок или мета-тег.
Другой распространенной ошибкой является блокировка для роботов файлов CSS и JavaScript, необходимых для рендеринга страницы. Google поменял свое отношение к этому вопросу и в настоящее время предупреждает об этом в поисковой консоли.
Исторически, Googlebot был схож с текстовыми браузерами типа Lynx, но сейчас он способен отрисовывать страницы в той же манере, что и современные браузеры. И это касается в том числе и выполняемых скриптов. И запрет доступа поисковым роботам к этим ресурсам может ухудшить их производительность и понизить место сайта в поиске. Вы можете проверять блокированные ресурсы в поисковой консоли и видеть “глазами” поискового робота Google в разделе “заблокированные ресурсы” поисковой консоли.
Меню ‘Просмотреть как Googlebot’ в поисковой консоли (увеличенная версия)
{kind=link}
Запомните, что в Chrome вы всегда можете сделать быстрый снимок того, как видит страницу Googlebot, введя в адресной строке cache:example.com/page и выбрав текстовую версию кэша.
Необрабатываемый контент
Несмотря на успехи Googlebot в рендеринге страниц, широкое использование Ajax и клиентских JavaScript фреймворков, таких как AngularJS, остается фундаментальным недостатком при поисковой оптимизации.
Проблема возникает из-за их зависимости от URL с хэшами (#). Идентификаторы фрагментов не являются частью HTTP-запросов и часто используются для перехода с одной части страницы на другую. Клиентские фреймворки отслеживают изменения в фрагмента с хэшем для динамических манипуляций со страницей без дополнительных запросов к серверу. Иными словами, они делают всю тяжелую работу.
Тяжелая работа это не то, что нравится поисковому роботу Google. Обходные пути существуют, но они требуют дополнительного времени при разработке и должны реализовываться в вашем рабочем процессе с самого начала проекта.
Предложенное Google в 2010 году решение требует замены хэшей сочетанием хэша и восклицательного знака (хэшбэнг — #!). Обнаружив, что на вашем сайте поддерживается такая схема URL, Googlebot модифицирует каждый URL по следующему образцу:
Original: yourdomain.com/#!content
Modified: yourdomain.com/?_escaped_fragment_=content
Весь фрагмент после хэшбэнга передается на сервер как специальный параметр URL, называемый _escaped_fragment_. Ваш сервер должен быть специально настроен, чтобы отвечать на такие запросы, отдавая снимок динамического содержимого в виде статического HTML.
У этого подхода множество недостатков. Хэшбэнги являются неофициальным стандартом плохой доступности и они разрушают природу веба. Короче, это специальный костыль SEO, не устраняющий причину проблемы.
HTML5 предлагает лучшее решение в виде использования History API (подробно описано на сайте Dive Into HTML5). Метод pushState позволяет манипулировать историей браузера, изменяя URL, появляющийся в адресной строке без дополнительных запросов к серверу. В результате у нас есть все плюсы как от интерактивности JavaScript, так и от ясной структуры URL.
Original: yourdomain.com/#content
Modified: yourdomain.com/content
Это решение не является волшебной пулей. Наш сервер должен быть сконфигурирован для того, чтобы отдавать отрендеренный на сервере HTML в ответ на запрос этих чистых URL , это обычно достигается с помощью изоморфного JavaScript. При удачной имплементации становится возможным создание продвинутых JavaScript приложений, доступных для поисковых роботов и отвечающих принципам прогрессивного улучшения. Поддержка в браузерах свойства pushState неплохая, все современные браузеры, начиная с IE10 поддерживают History API.
Наконец, будьте осторожны с контентом, недоступным для роботов. Флэш, Java апплеты и прочее плагино-зависимое содержимое обычно игнорируется или девальвируется поисковыми движками — поэтому избегайте всего этого, если вы заинтересованы в индексации контента.
Скорость и адаптированность к мобильным устройствам
Алгоритмы поисковых движков стали очень чувствительны к удобству пользователей, наиболее известными примерами этого являются учет скорости страниц и адаптации к мобильным устройствам. Так как невозможно изложить такие огромные темы в контексте данной статьи, мы ограничимся лишь обзором базовых принципов того и другого.
Поисковые движки поддерживают различные мобильные конфигурации, включая отдельные URL для мобильной версии сайта (например, через поддомен m) или динамическую передачу разного содержимого с помощью серверных заголовков Vary. Но на данный момент Google предпочитает подход, основанный на отзывчивом веб-дизайне. Если вы незнакомы с современной фронтенд разработкой или просто жили в лесу последние 5 лет, вам стоит начать со Smashing Book 5 в качестве введения в процесс разработки с отзывчивым дизайном.
Скорости страницы также должно уделяться повышенное внимание. Это не просто, большое время загрузки повышает показатель отказов; Google показывает, что скорости загрузки влияет на алгоритм ранжирования.
Существуют десятки инструментов, позволяющих выявить проблемы, замедляющие ваш сайт. Один из лучших вариантов — GTmetrix, на этом сайте доступно как платное, так и бесплатное тестирование на основе правил Google PageSpeed и Yahoo YSlow, а также вывод данных в наглядной форме.
Правильные первые шаги включают в себя:
- Gzip-сжатие на сервере
- Минификация стилей и скриптов
- Активация браузерного кэширования с заголовками
Expires - Уменьшение количества HTTP-запросов (с распространением HTTP/2 эта рекомендация будет менее важной)
Возможно, лучшим на данный момент введением в проблемы производительности и скорости загрузки страниц является книга Лары Хоган “Designing For Performance”. Это очень практичное руководство для разработки с учетом приоритета производительности, также включает отличный разбор процесса рендеринга страниц в браузере. Книга выложена в сети бесплатно, но так как прибыль идет на привлечение женщин к программированию, ее однозначно стоит купить.
И наконец — ориентируйтесь на то, что значение удобства пользователей для поисковых алгоритмов будет только возрастать. Даже безопасность является ранжирующим фактором; Google анонсировал в конце 2014 года, что сайты, использующие HTTPS будут иметь преимущество перед сайтами, его не использующими.
Эффективное сканирование и индексация
Итак, мы подготовили сайт для поисковых систем, теперь пришло время оценить как его содержимое интерпретируется и индексируется.
Мы начнем с рассмотрения одного из ключевых принципов дизайна сайтов, адаптированных к органическому поиску: дублирования контента. Вопреки популярному мнению, эта фраза не относится к буквальному дублированию страниц на сайте. Как всегда в SEO, мы должны рассматривать наш сайт с точки зрения робота. Следовательно, когда мы говорим о дублировании контента, мы просто говорим об URL, соответствующих одновременно следующим критериям:
- Возвращают HTTP-ответ
200ОК, сообщающий, что ресурс существует. - Возвращают контент, доступный по другим URL (дублирующий) или не имеющий ценности для пользователей.
Эти критерии можно продемонстрировать следующими примерами из онлайн-магазина одного из популярных британских ритейлеров.
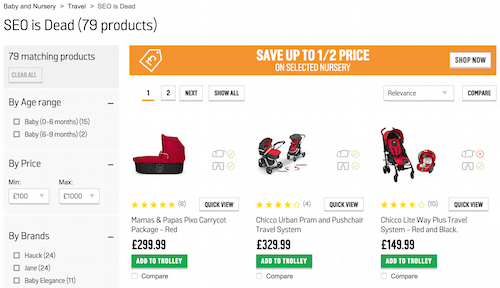
Пример 1. Argos.co.uk. (увеличенная версия)
{kind=link}
Здесь каждый продукт доступен через бесчисленное количество бессмысленных категорий. Это и есть пример дублирования контента: по всем этим URL проходит и индексирует поисковый робот, что означает пустую трату бюджета сканирования.

Пример 2. Argos.co.uk. (увеличенная версия)
{kind=link}
В данном случае, на страницах результатов поиска — даже тех, на которых не оказалось ни одного товара, отсутствуют какие-либо директивы запрета индексации и они полностью открыты для поисковых роботов. Это хороший пример контента, не имеющего ценности для пользователей — эти, как правило, пустые страницы не несут полезной нагрузки при том, что к моменту написания статьи их проиндексировано 22 тысячи.
Прекрасно известно, что алгоритм Google наказывает сайты за масштабное дублирование такого рода и это делает особо проблематичным использование систем фасетной навигации. И даже небольшие проблемы могут со временем разрастись. Особенности поведения вашей CMS или проблемы с настройками сервера могут привести к серьезной трате бюджета сканирования и разбавлению так называемого “веса ссылок” (ценности внешних ссылок на ваши страницы — подробнее об этом в третьем разделе). Очень часто веб-мастера совершенно не замечают этих проблем.
Наша первоочередная цель это консолидация всего дублирующего, малоценного или устаревшего содержимого. В одной статье нельзя обойти ни все возможные сценарии, которые могут возникнуть, ни подходы к их смягчению. Вместо этого, мы рассмотрим инструменты, которые позволяют диагностировать проблемы при их возникновении.
Диагностика индексирования
Вы можете узнать очень многое об индексации вашего контента, используя продвинутые операторы поиска.
Ввод в Google запроса site:yourdomain.com вернет все проиндексированные URL с домена. Последние страницы в полученном списке Google считает наименее релевантными — и это может дать ключ в выявлению проблем дублирования, влияющих на ваш сайт. Если вы видите ремарку о том, что Google скрыл некоторые результаты, очень похожие на уже представленные, нажмите на ссылку “Показать скрытые результаты”, просмотр нефильтрованного содержимого поисковой выдачи это отличный способ раскрыть серьезные проблемы.

Всегда просматривайте скрытые результаты поиска для диагностики проблем. (увеличенная версия)
{kind=link}
Оператор site: становится еще мощнее в сочетании с операторами inurl, intitle, exact ("...") и негативным оператором (-). Используя эти и другие продвинутые операторы в своем исследовании, вы можете быстро диагностировать отдельные большие проблемы:
-
Проверьте возможное попадание в индекс поддоменов и тестовых сайтов. Например, если ваш сайт работает с поддомена
www, проверьте наличие в индексе URL без него.site:yourdomain.com -inurl:www
-
Проверьте наличие множественных версий домашней страницы с помощью поиска по тегу
<title>, очень часто корневой домен и заглавная страница индексируются отдельно:yourdomain.com/index.htmlиyourdomain.com.site:yourdomain.com intitle:”Your Homepage Title”
-
Проверьте URL с добавлением параметров, не изменяющих содержимое страницы, необязательно в определенном каталоге. Идентификаторы сессий и аналитика партнерских сетей особенно распространены в электронной коммерции и легко могут повлечь тысячи дублированных страниц.
site:yourdomain.com/directory/ inurl:trackingid=
Поисковая консоль Google предоставляет отличную платформу для мониторинга состояния сайта. Панель “Оптимизация HTML” из раздела “Вид в поиске” это хороший способ отмечать дублирующийся контент. Уделите отдельное внимание списку страниц с одинаковыми тегами <title> и метаописаниями, это позволит выявить проблемы с дублированием контента и неправильной разметкой страниц.
Перейдя в панель “Статус индексирования” раздела “Индекс Google” вы увидите историю индексации вашего сайта. В режиме “расширенные данные” вы совместите эти сведения с данными о заблокированных вами адресах в robots.txt.
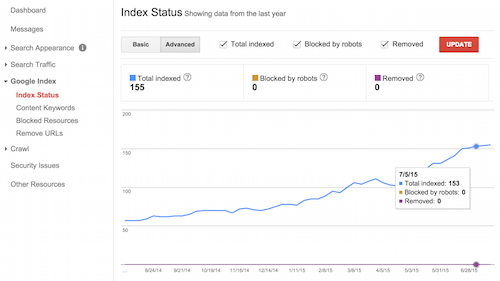
График индексирования сайта в поисковой консоли с учетом URL, заблокированных в robots.txt. (увеличенная версия)
{kind=link}
Обязательно проверьте сайт на наличие “мягких 404 ошибок” в панели “Ошибки сканирования” раздела “Сканирование”. Это ситуации, когда при попытке зайти на несуществующую страницу не возвращается соответствующий код 404. Запомните, для поискового робота содержимое страницы не связано с HTTP-ответом сервера. Пользователи могут видеть сообщение “Страница не найдена”, но для роботов эти страницы существуют (а, значит, должны быть проиндексированы) в результате неправильной обработки ошибок на сервере
Наконец, взгляните на панель “Файлы Sitemap” в том же разделе. Кроме того, что здесь вы можете проверить и добавить свою карту сайта, также вы можете видеть как Google и другие поисковые движки интерпретируют структуру вашего сайта. Особое внимание уделите соотношению добавленных и проиндексированных URL, большая разница между этими значениями может свидетельствовать о наличии проблем с дублирующим или малоценным контентом.
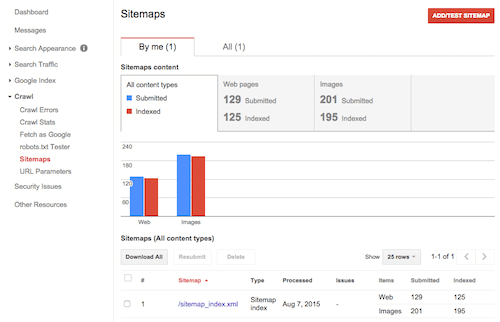
Соотношение добавленных и проиндексированных URL в поисковой консоли. (увеличенная версия)
{kind=link}
Настройка сервера и редиректов
В ситуациях, когда дублирующий или устаревший контент имеет очевидный “новый” URL — например, замененная старая страница, лучшим способом решения проблемы будет серверный редирект. Посетители будут незаметно перемещаться на новый адрес, а поисковые роботы будут понимать, что оригинальная страница перенесена.
В таких случаях сервер всегда надо настраивать на возвращение ответа 301 (постоянный перенос), а не 302 (временный перенос, в Apache работает по умолчанию). Люди не заметят разницу, но роботы интерпретируют эти ответы совершенно по-разному. В отличие от временного редиректа, постоянный редирект:
- Влечет удаление старого URL из поискового индекса.
- Передает вес ссылок старой страницы новой странице, подробнее эта концепция будет рассмотрена в последнем разделе статьи.
Реализация этого будет сильно отличаться в зависимости от вашей настройки сервера, но я продемонстрирую некоторые основные примеры в Apache, используя файл конфигурации .htaccess. Особо сложная маршрутизация редиректов обычно требует использования модуля mod_rewrite, но не стоит недооценивать возможности директив Redirect и RedirectMatch в простом mod_alias. Следующий код делает редирект отдельного файла и целого каталога вместе с содержимым на новые адреса с 301 ответом сервера:
Redirect 301 /old-file.html http://www.yourdomain.com/new-file.html
RedirectMatch 301 ^/old-directory/ http://www.yourdomain.com/new-directory/
Более подробное руководство по использованию этих директив есть в документации Apache.
В условиях, когда мы ищем дубликацию адресов структурного характера, вроде упоминавшейся проблемы с поддоменом www, мы можем использовать правила для перезаписи URL.
Наша цель состоит в том, чтобы обеспечить доступность нашего сайта по выбранному имени хоста: www.yourdomain.com (не важно, выбираете вы вариант с www или без, главное, что вы реализуете его последовательно). Запрос URL без www должен перенаправлять пользователя с кодом 301 на соответствующую каноническую версию. Пользователи плавно попадают на нужную страницу, а поисковые роботы знают, какие URL надо индексировать. Это достигается следующими директивами mod_rewrite:
RewriteEngine on
RewriteCond %{HTTP_HOST} ^yourdomain.com [NC]
RewriteRule ^(.*)$ http://www.yourdomain.com/$1 [L,R=301]
Как и в прошлом примере, подробное руководство есть в документации Apache. Также документация есть и по аналогичным модулям Nginx и IIS.
Актуальность перезаписи URL в SEO это не только простые исправления. Более важно то, что она позволяет делать ресурсы доступными по HTTP с адресами, не коррелирующими с их реальным местоположением в файловой системе. Это позволяет нам реализовать статичную, человекочитаемую структуру URL отражающую логичную информационную архитектуру сайта.
- Оригинал:
http://www.yourdomain.com/content/catID/43/prod.html?p=XjqG - Перезапись:
http://www.yourdomain.com/category/product/
Преимущества логичной структуры URL для SEO сложно переоценить. В дополнение к повышению эффективности сканирования, удачная реализация значительно улучшает удобство пользователей. Помните, что URL является одним из видимых для пользователя элементов, когда тот решает на какую ссылку перейти со страницы поисковой выдачи.
С учетом всего стека возможных технологий, методология может значительно меняться, но общий подход сформулирован в руководстве Google по лучшим практикам URL, также полезное введение в условия перезаписи URL есть на Linode.
И в завершение темы редиректов: избегайте цепных редиректов насколько это возможно. Не столько из-за их неээфективности для сканирования — ценность каждого последующего редиректа 301 уменьшается. Вашей целью должно быть перенаправление со всех вариантов устаревших страниц на один корректный URL одним постоянным редиректом. Более подробно концепция сохранения ценности ссылок изложена в разделе 3.
Канонический тег
В ситуациях, когда переадресация на сервере недоступна или нецелесообразна, у нас есть еще одно решение проблемы: элемент link с атрибутом rel="canonical" (далее - канонический тег).
Впервые представленный в 2009 году как результат совместных усилий Google, Bing и Yahoo, этот тег сообщает поисковым системам о предпочитаемом URL для страницы. Использовать его просто: добавьте элемент link с атрибутом rel="canonical" в секцию head нужной страницы и всех ее вариантов.
Вот образец его использования на простой домашней странице:
http://www.yourdomain.comhttp://www.yourdomain.com/index.htmlhttp://www.yourdomain.com?sessionid=1988
Пометка всех этих страниц следующим тегом сообщает поисковым движкам, какую версию показывать пользователям:
<link rel="canonical" href="http://www.yourdomain.com">
В отличие от редиректов, канонический тег не влияет на URL, показываемый пользователю в адресной строке. Это просто трюк для поисковых систем, позволяющий обрабатывать разные варианты как одну страницу. URL в каноническом теге должен быть корректным; если ваши канонические теги будут вести к ошибке 404 (или канонический тег для всех страниц будет вести на одну страницу) это приведет к катастрофе для сайта.
Обратите внимание, что в большинстве случаев серверная переадресация является более продуктивным и понятным для пользователей способом решения проблем с дублированием. И если у вас есть возможность контролировать архитектуру сайта, то вы можете избежать большинства сценариев, требующих использования канонического тега в качестве фикса.
Как упоминалось, есть смысл в подключении самоссылающихся канонических тегов на каждой странице. При правильной реализации они являются первой линией защиты против непредвиденных проблем. Если ваш сайт использует параметры для идентификации конкретных комментариев пользователей (например, …?comment=13), канонический тег гарантирует, что такие страницы не будут индексироваться и дублировать основные.
Когда вы сталкиваетесь с дублированием контента, вы всегда должны смотреть на адреса страниц как на основную причину проблем. Поэтому отключение проблемного параметра и обработка его функционала с помощью куки является предпочтительным решением по сравнению с блокированием параметра в привязанном к производителю сервису типа Google Search Console или Bing Webmaster Central. Более детальный обзор по проблеме дублирующему контенту и путях ее решения, есть в статье Пита Майерса на Moz.com.
Мультирегиональность и многоязычность
Вебсайты, ориентированные на глобальную или многоязычную аудиторию могут создать особенно много хлопот с точки зрения поиска, учитывая, что они изначально умножают содержимое за счет многоязычности. Международная поисковая оптимизация это чрезвычайно широкая тема, сама по себе требующая отдельной статьи, по этой причине мы затронем лишь ее основы.
Структура многоязычного сайта требует тщательного рассмотрения. Руководство по интернационализации от Google будет хорошей стартовой точкой. Нужно учитывать десятки факторов перед тем как выбирать отдельные домены национального уровня, поддомены и подкаталоги, при этом необходимо планировать будущее развитие сайта до его развертывания.
Независимо от выбранных вам способов, атрибут rel="alternate" hreflang="x" используется для сообщения поисковым движкам о том, что указанную страницу надо выдавать пользователям на определенном языке. Это сигнал, а не императив — поэтому другие факторы (настройки таргетинга по странам в поисковой консоли или IP-адрес сервера) могут переписать его.
Аннотации hreflang могут передаваться в заголовках HTTP, в картах сайта или с помощью тегов link в head ваших страниц. Синтаксис для последнего варианта следующий:
<link rel="alternate" href="http://yourdomain.com/en" hreflang="en">
<link rel="alternate" href="http://yourdomain.com/de" hreflang="de">
<link rel="alternate" href="http://yourdomain.com/fr" hreflang="fr">
<link rel="alternate" href="http://yourdomain.com/fr-ca" hreflang="fr-ca">
Значение атрибута hreflang определяет язык согласно стандарту ISO 639-1 и (дополнительно) регион по стандарту ISO 3166-1 Alpha 2. В примере выше, определены четыре версии домашней страницы: английская, немецкая, французская (без привязки к региону) и французская для Канады. Каждая версия страницы должна определять каждый переведенный вариант, в том числе себя. Иными словами, приведенный ваше блок должен быть повторен на всех четырех версиях домашней страницы. И, наконец, учитывайте, что Google не рекомендует использовать канонические теги на различных интернационализированных версиях страниц — используйте canonical только в пределах одного языка.
Интернационализация может вызвать сложности и стоит поэкспериментировать с инструментами типа Hreflang Tags Generator от Алейды Солис и полностью изучить документацию Google, прежде чем думать о внесении изменений на сайте.
В завершении темы мультирегиональности стоит отметить, что локализация SEO увеличивает возможности местного бизнеса. В качестве введения стоит использовать текст от Мэтью Бэрби по этой теме на Search Engine Land.
Поддержка и лучшие практики
В этом разделе мы обсудим общие лучшие практики технического SEO. Это включает в себя аудит метаданных страницы — названия, описания,заголовков, а также проверки общих внутренних проблем, которые легко упустить из виду.
В тандеме с поисковой консолью Google или средствами веб-мастера Bing, наиболее полезным инструментом в SEO является симулятор поискового робота. Это разновидность программного обеспечения, используемая для прохода по сайту, аналогичного действиям поискового робота. Неплохим представителем таких программ является Xenu Link Sleuth, но для серьезной работы лучше всех Screaming Frog SEO Spider.
‘The Frog’, как ее обычно называют, позволяет полностью настроить пользовательского агента, быстро просканировать сайт с указанной глубиной (может принимать паттерны в виде регулярных выражений) и соблюдением директив nofollow / canonical / robots.txt. Полученные данные можно фильтровать и экспортировать в формате CSV или Excel, что открывает бесчисленные возможности для их дальнейшего исследования.
В качестве простого образца мы проведем аудит метаданных на странице. После собственно содержания страницы, наибольшее значение для современного SEO имеет содержимое тега title и метатега description, их мы и рассмотрим.
В меню Configuration – Spider снимите проверку изображений, CSS, JavaScript, SWF и внешних ссылок. Затем выберите Crawl All Subdomains, чтобы обеспечить проверку всего домена и нажмите OK. Введите URL домена в поле спайдера и нажмите Start.
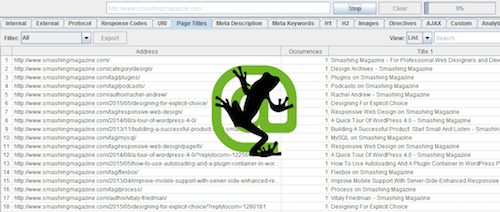
Screaming Frog SEO Spider проходит все URL домена. (увеличенная версия)
{kind=link}
Вкладки Page Titles и Meta Descriptions позволяют вам отфильтровывать данные сканирования по возникающим проблемам — в случае с тегами title это отсутствующие, дублирующие, слишком короткие или слишком длинные теги. Нажмите Export, чтобы экспортировать данные в таблицу для последующего изучения.
Если вы никогда раньше не запускали сканер ссылок на своем сайте, то почти наверняка в результатах проверки найдется что-либо, что вас удивит. Это может быть неожиданная проблема из-за дублирования, устаревшая и забытая секция сайта или важная страница без метаданных. Именно в этом ценность инструментов, таких как Screaming Frog — они дают понимание того, как поисковые роботы взаимодействуют с вашей страницей.
Официальная документация этой программы исчерпывающа, а также есть отличное руководство для продвинутых пользователей от Эйчли Бушнелл.
Вот краткий список того, что стоит проверить для оценки эффективности поискового сканирования:
- Временные редиректы (с кодом
302). - Цепные редиректы — используйте функцию отчета о них.
- Непоследовательность внутренних ссылок — ссылки на неканонические URL, например.
- Использование устаревших метатегов типа ключевых слова — они только обманывают посетителей.
Поддержка ссылочного профиля
Восхождение Google как главного поисковика в конце 90х отчасти объясняется учетом внешних ссылок как фактора ранжирования.
Сооснователь компании Ларри Пэйдж создал технологию PageRank, то есть способ измерения качества страницы, основанный на числе других сайтов (и, главное, на значимости этих сайтов), ссылающихся на нее. С практической точки зрения это означает, что ссылка на ваш сайт с BBC повлияет на ваш поисковый рейтинг намного сильнее, чем ссылка откуда-либо еще.
Визуализация алгоритма PageRank (источник изображения — Wikimedia Commons, (увеличенная версия))
{kind=link}
{kind=link}
Алгоритм Google значительно эволюционировал за годы с момента его появления и сейчас учитывает десятки метрик, влияющих на рейтинга страницы. Тем не менее, внешние ссылки остаются самым важным фактором для поискового ранжирования.
Все это привело к грязной истории с ссылочным спамом и наказанием за него, в которой недобросовестные оптимизаторы открыли тактику построения ссылок, давшую им возможность масштабных нарушений пока Google неспешно реагировал. В так называемом обновлении “Пингвин” Google ответил в этой войне, наказав сайты за платные ссылки, ссылочный спам и прочие нарушения рекомендаций.
В результате аудит линков в SEO это прежде всего аудит рисков — свидетельств предыдущих попыток манипулировать PageRank, а не возможностей ссылок. В отдельных высоко-конкурентных индустриях (например, в азартных играх и фармацевтике) вебмастеру надо беспокоится о возможных эффектах поискового спама и негативного SEO в отношении ранжирования их сайта; в некоторых случаях бывает необходимым постоянное активное использование отклонения обратных ссылок. Однако это крайние варианты.
С другой стороны, таргетинг ссылок подходит всем сайтам. Оценивая состояние ссылочного профиля сайта можно сохранять вес ссылок (значение, которое Google придает ссылке) самыми разными способами.
Потеря веса ссылок
Вес ссылок можно рассматривать как ценную жидкость, а ссылки на ваш сайт, как трубы, по которым она транспортируется. Целый комплекс труб. Обычная ссылка, ведущая непосредственно на URL, возвращающий ответ 200 ОК, то есть на живую страницу — делает свою работу нормально. Ссылка на “мертвую” страницу, возвращающую ошибку 404 или 503 спускает всю ценность в канализацию и ваш сайт не получает ничего.
Один ответ с 301 редиректом работает как воронка, он захватывает большую часть веса ссылки и передает его на новое назначене. Он делает свое дело, но это негерметичный процесс и для предотвращения потерь вас надо избегать цепных редиректов.
302 редирект это решето. Несмотря на то, что он переведет всех пользователей на нужную страницу, вес ссылки полностью теряется. Ссылки (или редиректы) на страницы, заблокированные в robots.txt также неэффективны при передаче веса ссылок. Я не буду развивать эту аналогию дальше, но цикличных редиректов и “мягкой ошибки 404” также стоит избегать.
Существуют и другие факторы, которые надо учитывать, прежде чем исправлять потерю веса ссылок. Первое — вес ссылок для каждого поддомена расчитывается отдельно. Несмотря на некоторые утверждения об обратном, поисковые движки воспринимают forum.yourdomain.com и www.yourdomain.com как разные сайты и ссылки на один из них ничего не прибавляют второму. Именно поэтому блоги, размещаемые на внешнем ресурсе типа Tumblr (yourblog.tumblr.com) ничего не получают от авторитета корневого домена. Именно по этой причине стоит устанавливать компоненты сайта (форумы, блог и т.д.) в подкаталоги основного домена.
Более того, можно предотвратить передачу веса по определенным ссылкам, задав для них атрибут nofollow. Это можно сделать и сразу для всех ссылок на странице с помощью метатега для роботов — и они не будут переходить по ссылкам и передавать им значимость. Также значение nofollow можно задать атрибуту rel ссылки, это даст тот же эффект: <a href="/" rel="nofollow">.
Влияние вышеперечисленных проблем имеет наибольшее значение для старых и больших сайтов. Побочные эффекты миграций, ребрендинга, изменения структуры URL и интернационализации с течением времени усугубляются. К счастью, затраты на исправление этих проблем нужны небольшие, в то время как эффект может быть значительным.
Перекрываем утечки
Чтобы выявить и исправить эти проблемы нам нужен список всех ссылок на сайт. Существует большое количество сервисов, предлагающих акие услуги, лучшими из них считаются Majestic и Ahrefs. Мы будем использовать последний.
Нам надо сгенерировать простой отчет по ссылочному профилю нашего корневого домена. Вводим адрес в Ahrefs Site Explorer, нажимаем Export – CSV и скачиваем отчет Backlinks/Ref в нужном формате (UTF–8 для Libre Office Calc, UTF–16 для Microsoft Excel).
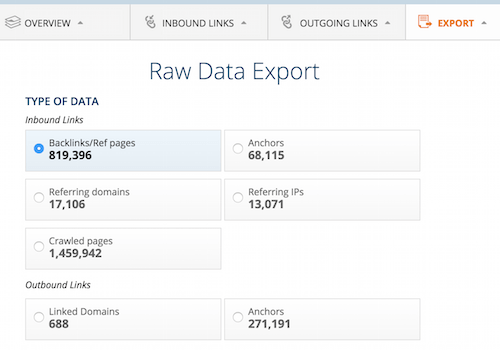
Экспорт отчета в Ahrefs.com. (увеличенная версия)
{kind=link}
Используйте индексатор типа Screaming Frog или бесплатные Seo инструменты для Excel для обхода URL ваших ссылок. Если вы используете Screaming Frog, настройте в нем следование редиректам (вне зависимости от длины цепи) и игнорирование правил disallow в robots.txt. Отчет по цепям редиректа экспортирует полный путь робота к каждому URL.
Итак, мы получили данные, что делать дальше? Оливер Мэйсон написал отличное руководство по этому вопросу на сайте Builtvisible:
Что мы пытаемся сделать, чтобы обеспечить поисковому роботу Google беспрепятственный проход от внешней ссылки до канонической страницы за минимальное количество шагов? Мы выявляем все, что может помешать сканированию или передачи веса ссылки. Общие руководства по миграции и структуре URL ориентируют на то, что старая структура переадресуется к новой в один заход. Это подходит для идеальных условий, но с учетом предыдущих миграций вам гарантирована потеря ссылочного капитала. Очень часто вы будете сталкиваться со структурными изменениями, не обработанными как надо в свое время и влекущими неэффективность.
Если вы сталкивались с подобным, вы должны догадаться, как это исправить. Исключая возможность ручной перенастройки (не обращаясь с просьбой обновить ссылки ко всем веб-мастерам), вы можете решить эти проблемы следующим образом:
- Чтобы возвратить вес ссылок на страницы с ответами
404или503, сделайте постоянный редирект на наиболее близкие существующие страницы. - Замените все временные редиректы (
302) постоянными (301) - Если ссылки ведут на ресурсы заблокированные в
robots.txt, создайте для исключениеAllowили сделайте редирект на незаблокированную страницу. - Удалите все промежуточные шаги из цепей редиректов, от внешней ссылки до канонической страницы должно быть не более одного постоянного редиректа.
Если у вас большой сайт и ограничены ресурсы разработки, вы можете сосредоточиться на тех проблемных URL, на которые ведет большее количество ссылок с разных доменов. Запомните также, что исправление случаев полной потери веса ссылок (например, вы создали новый редирект для ранее популярной страницы ныне возвращающей 404) будет иметь более значительный эффект, чем малозначительные изменения.
Освоение истории
И, наконец, учитывайте историю домена вашего сайта. Если были большие миграции или ребрендинг со сменой корневого домена (переход с .co.uk на .com) — стоит лишний раз убедиться, что этот процесс был проведен правильно. Правильные советы есть в рекомендациях Google по миграции сайтов.
Вам придется повторить все вышеуказанные шаги для каждого свойства домена вашего бренда, чтобы обеспечить правильный редирект со старой страницы на соответствующую новую. Также стоит использовать инструмент Change of address в поисковой консоли Google.
Все это делает после реализации редиректов и требуют от вас подтверждения владения старым и новым доменами. Для особо старых доменов это, возможно, придется делать с помощью DNS TXT-записи. Может показаться, что это лишняя трата усилий, но это может дать значительный прирост органического поиска.
Сохранение и восстановление веса ссылок это ключевая причина подключения опытного специалиста в техническом SEO при миграции или реструктурировании сайта. Это особо важно для сайтов электронной коммерции, доходы которых напрямую зависят от успешности органического поиска. Осторожное планирование и всесторонняя маршрутизация редиректов должны делаться заранее, чтобы сохранить накопленный рейтинг сайта.
Вершина айсберга
Я надеюсь, что эта статья продемонстрировала, что техническое SEO это необычайно богатая дисциплина.
Рассмотренные нами принципы и техники это хороший набор лучших практик, но как и в других областях веб-разработки, у каждого правила есть свои исключения. Подготовка миграции для большого сайта электронной коммерции, работающего на самописной CMS, с миллионом страниц и мобильной версией, фасетной навигацией и большой историей архитектурных изменений и ребрендинга требует понимания другого уровня.
Для тех, кто хочет лучше понять продвинутое техническое SEO, хорошим началом будет анализ логов. Для особо сложных сайтов следование принципам может помочь только в какой-то степени; настоящая органическая оптимизация требует точного знания того, как поисковые роботы взаимодействуют с вашим сайтом. Экспортировав серверные логи для анализа можно увидеть каждый запрос от поисковых систем. Эти данные позволяют определять частоту, глубину и охват сканирования и показывает проблемы, которые могут не заметить даже опытные SEO-специалисты. Я настойчиво рекомендую рекомендации Дэниэла Батлера для всех, кто хочет открыть для себя возможности анализа логов.
То, что мы рассмотрели это лишь вершина айсберга. Даже технически оптимизированные сайты могут добиться большего от органического поиска при правильном расчете.
Такие вещи, как социальные метатеги, могут улучшить потенциал вашего контента на Facebook, Twitter и Pinterest; структурированные данные позволяют делать аннотации к контенту до машинной интерпретации и позволяют Google и Bing генерировать “красивые” сниппеты. Словарь Schema.org и формат JSON-LD открывают новые границы возможностей и дают возможность для целого массива действий, которые можно использовать непосредственно из результатов поиска. Но об этом как-нибудь в другой раз.
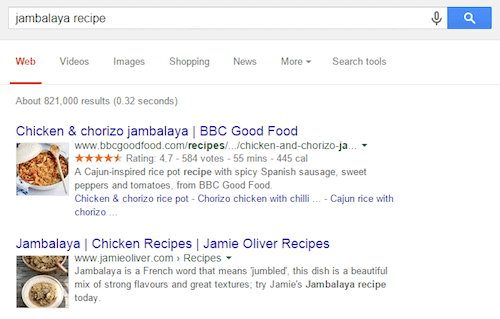
Красивые сниппеты - отличная возможность выделиться в органическом поиске. (увеличенная версия)
{kind=link}
Моей основной целью при написании этой статьи было объяснить веб-разработчикам основные понятия современной поисковой оптимизации. И я буду рад, если мне удалось при этом развеять некоторые мифы.
SEO это не темное искусство и оно совсем не умирает, также как настройка производительности сайта или адаптация к мобильным устройствам это просто один из способов создания лучшего веба.