Опыт масштабирования генератора статических сайтов
Оригинал статьи: Using A Static Site Generator At Scale: Lessons Learned
Оглавление:- Причины использования статических сайтов и наши задачи
- Чем больше контента, тем больше время сборки
- Избегаем привязки к конкретным технологиям
- Сервер: больше, чем статические сайты
- Редактирование контента с генератором статических сайтов
- Ресурсы
- Заключение
В наши дни генераторы статических сайтов вошли в моду. Как будто разработчики по всему миру внезапно осознали, что для большинства сайтов простой процесс сборки достаточен, а двадцатилетнее увлечение CMS было бесполезным. Это, конечно, слишком радикальное высказывание, но для обычного сайта без большого количества динамических частей оно очень близко к правде.
Однако, остается ли это правильным для сайта большего, чем ваш простой технический блог? Как ведут себя генераторы статики, когда количество страниц превышает необходимое для сайта-портфолио и приближается к тысяче? И когда разработкой занимается команда? Или люди с разным техническим уровнем? Это история о сайте на 2000 страниц, 40 авторах и технологии, созданной для хакеров.
Причины использования статических сайтов и наши задачи
Мы использовали генераторы статических сайтов в побочных проектах нашей компании, в которых было разумное количество контента: около 30-40 страниц информации о продуктах, иногда посадочные страницы и связанные с компанией веб-сайты.
У нас был хороший опыт с генераторами статических сайтов. Для продвинутых фронтенд-разработчиков использование генератора статических сайтов также просто как создание шаблонов, но с реальными данными и настоящим контентом. И это позволяет нам и нашим авторам контента легко масштабировать процесс.
Мы начали с популярного генератора Jekyll. Обычная страница содержит следущее:
- Вводная YAML — это радость для авторов и редакторов, так как они могут поместить туда любые метаданные, даже те, которые не используются сейчас, но будут использоваться в будущем.
- Markdown — дает базовую структуру контента. Он прост для понимания и написания, а множество редакторов дают возможность удобного предпросмотра.
- Блоки кода Liquid - шаблонизатор от Shopify Liquid очень мощный. В нем есть продвинутые циклы и условия, он легко расширяется с помощью плагинов, написанных на Ruby. Разработчики сделали для редакторов поддержку кастомных структурных элементов типа
{% section %}и{% column %}для лучшей организации страницы. - И, конечно, изображения — на каждой странице их от 5 до 15.
Типичная страница выглядит так:
---
title: Getting started with our product
layout: blue
headerImage: getting-started.svg
permalink: /getting-started/
---
{% section %}
# How to get started with our product
…
{% endsection %}
…
В общем, создание контента было простым как написание заметок в редакторе. Вся красота добавлялась после пропускания страницы через Jekyll.
В дополнение к легкости использования наших любимых текстовых редакторов, нам нравились и специфические преимущества статических сайтов, которые мы получали как разработчики и вебмастера (вы не слышали это слово довольно давно, не так ли?).
- В плане безопасности статические сайты это крепости. Нет никаких баз данных и динамических интерпретаторов на серверах, что чрезвычайно снижает риск взлома.
- Статические сайты невероятно быстры. Поместите его на CDN и он будет работать моментально по всему миру.
- Веб-разработчики любят гибкость. Изменение раскладки или добавление сайтов-сателлитов к содержимому не требует от вас погружения во внутренности системы управления контентом, также как не требует никаких хаков. Вы можете поддерживать эти ресурсы параллельно обычному содержимому и спокойно производить развертывание.
- Хранение всех служебных файлов и контента в системе контроля версий типа Git дает гибкость при публикации. Готовьте контент в отдельной ветке, объединяйте ее с основной и отправляйте на сервер в пару кликов в понедельник утром.

Использование Git в качестве хранилища, позволяет работать с контентом как с исходным кодом. Включая пулл-реквесты, рецензирование и версионирование. Это ставит авторов котента в один ряд с дизайнерами и разработчиками. (Изображение — Штефан Баумгартнер и Симон Людвиг) (Увеличенная версия)
{kind=link}
Наша команда из пяти человек была очень довольна результатами. Мы взяли идею из нашего маркетингового сайта и использовали ее на остальных проектах. Внезапно после нашего основного 40-страничного сайта нам пришлось делать руководство по стилю на 50 страниц. Затем 150 страниц документации. Затем почти все для нашей смежной компании и количество страниц достигло 2000. Вы не поверите, но наш технический стек был на грани истощения:
- Чем больше ваша страница, тем дольше она собирается. Генерация статических сайтов это проактивная компиляция исходного кода в страницы HTML. Она может занять часы, прежде чем ваш сайт будет готов к развертыванию.
- Выбор генератора статических сайтов равносилен ставке на одну CMS. Инструмент, ускоряющий вас поначалу, замедляет вас, когда перестает соответствовать вашим нуждам.
- Даже если весь ваш контент статический и вам не требуются данные от пользователей, существуют ситуации, когда вам понадобятся динамические данные.
- Технически подкованные редакторы любят работу с контентом как с исходным кодом программ. А их менее продвинутые коллеги…увы, у них все иначе.
Теперь посмотрим, как мы разобрались с каждым из вопросов.
Чем больше контента, тем больше время сборки
Одним из ключевых факторов генерации статических сайтов является проактивный подход к рендерингу. В традиционных системах управления контентом (CMS) каждая страница рендерится для каждого визита (мы не учитываем здесь алгоритмы кэширования). Генератор статических сайтов создает все страницы сразу. И хотя этот процесс быстр, время генерации линейно увеличивается соответственно увеличению количества контента. Особенно, если процесс включает автогенерацию и автооптимизацию отзывчивых изображений из скриншотов от 200 пикселей до HD изображений шагом в 200 пикселей. Даже с нашей стартовой настройкой из 40 страниц и примерно 300 изображений, сборка занимала около двух часов от начала до окончания на наших CDN. Это не то время, которое вы хотите подождать, чтобы увидеть, исправили ли вы ошибку в заголовке или нет. Предвосхищая то, что ожидало нас в ближайшем будущем мы должны были принять несколько важных решений.
Разделяй и властвуй собирай
Даже если ваш стек технологий способен генерировать тысячи страниц, это не обязательно делать. Не всякая часть контента должна знать о существовании остальных. Немецкоязычный сайт может обрабатываться отдельно от англоязычной версии. А документация это область совершенно отдельная от основного сайта компании.
Части контента не только являются дискретными, они также расходятся в частоте обновления. Блог обновляется несколько раз в день, основной сайт компании несколько раз в неделю, сайт с документацией каждые две недели вместе с обновлением продукта. А наша книга о производительности Java? Пару раз в год.
Это все привело нас к разделению наших сайтов на пакеты контента и технические репозитории. Пакеты контента это репозитории Git, содержащие все, что может изменять автор или редактор: файлы markdown, изображения, дополнительные данные. Для каждой сущности мы создали репозиторий с одинаковой структурой.
 Техническим репозиторием можно считать машину, конвертирующую несколько репозиториев контента в готовые статические сайты.(Изображение — Штефан Баумгартнер и Симон Людвиг) (Увеличенная версия)
Техническим репозиторием можно считать машину, конвертирующую несколько репозиториев контента в готовые статические сайты.(Изображение — Штефан Баумгартнер и Симон Людвиг) (Увеличенная версия)
{kind=link}
Технические репозитории с другой стороны содержат все, чем занимаются разработчики: код фронтенда, шаблоны, плагины для контента и систему сборки для генерации статического сайта.
Наши сборочные серверы настроены на прослушивание каждого из этих репозиториев Git. Изменение в репозитории с контентом вызывает отдельную сборку пакета контента. Изменение в техническом репозитории запускает сборку только в соответствующем репозитории с контентом. В зависимости от количества репозиториев с контентом это может значительно снизить время сборки.
Инкрементальная сборка
Еще важнее, чем разделение контента на отдельные пакеты, был метод работы с изображениями. Целью была генерация каждого скриншота нашего продукта в различных размерах от 200 пикселей для достижения отзывчивости. Каждое сгенерированное изображение оптимизируется в gulp-imagemin. В каждой сборке этот процесс занимает немалую часть из затрачиваемых двух часов.
Хотя два часа сборки были необходимы для самой первой сборки, в каждой последующей это пустая трата времени. Не каждое изображение меняется в каждой сборке. Большая часть работы уже сделана, так зачем каждый раз ее повторять? Инкрементальные сборки стали ключом к тому, чтобы избавить нас и наши сборочные серверы от объемной работы.
Наша обработка изображений делалась в Gulp. Плагин gulp-newer это именно то, что нам нужно для инкрементальных сборок. Он сравнивает временные отметки каждого файла в каталоге-исходнике с тем же файлом в каталоге-назначении. Если временная метка исходника новее, он идет в сборку, если нет — отбрасывается. Генерация всех отзывчивых изображений стала основой для подключения всех плагинов в правильном порядке:
const merge = require('merge2');
const rename = require('gulp-rename');
const newer = require('gulp-newer');
const imagemin = require('gulp-imagemin');
…
/*
The options in this case are an array of image widths. In our
case, we want responsive images from 200 pixels
up to 1600 pixels wide.
*/
const options = [
{ width: 200 }, { width: 400 },
{ width: 600 }, { width: 800 },
{ width: 1000 }, { width: 1200 },
{ width: 1400 }, { width: 1600 }
];
gulp.task('images',() => {
/*
We can map each element of this array to a Gulp stream.
Each of those streams selects each of the original images
and creates one variant.
*/
const streams = options.map(el => {
return gulp.src(['./src/images/**/*'])
/*
We follow a naming convention of adding a suffix to
the file's base name. This suffix is the image's target
width.
*/
.pipe(rename(file => file.basename += '-' + el.width))
/*
This is where the "incremental" builds kick in.
Before we run the heavy processing and resizing tasks,
we filter elements that don't have any updates.
This Gulp tasks checks whether the results in "images" are
older than the source items.
*/
.pipe(newer('dist/images'))
.pipe(resize(el))
.pipe(imagemin())
.pipe(gulp.dest('dist/images'));
});
return merge(streams);
});
В отсутствие хорошего плагина для изменения размеров изображений мы сделали свой. Это было как раз то время, когда мы решили прекратить обрабатывать неизмененные файлы. Если размер изображения не мог быть изменен, так как превышался размер оригинала, мы прекращали процесс обработки этого изображения. Следующий фрагмент кода использует для выполнения этой задачи пакет Node.js GraphicsMagick.
const gm = require('gm');
const through = require('through2');
module.exports = el => {
return through.obj((originalFile, enc, cb) => {
var file = originalFile.clone({contents: false});
if (file.isNull()) {
return cb(null, file);
}
const gmfile = gm(file.contents, file.path);
gmfile.size((err, size) => {
if(el.width < size.width) {
gmfile
.resize(el.width,
(el.width / size.width) * size.height)
.toBuffer((err, buffer) => {
file.contents = buffer;
/* add resized image to stream */
cb(null, file);
});
} else {
/* remove from stream */
cb(null, null);
}
});
});
};
С инкрементальным добавлением файлов нам нельзя забывать о необходимости удалять из каталога-назначения файлы, удаленные из исходников. Нам не нужны остатки от предыдущих сборок, добавляющие лишний вес сайту при развертывании. Система сборки Gulp поддерживает промисы, поэтому у нас есть много плагинов, основанных на промисах и реализующих эту функциональность.
const globby = require('globby');
const del = require('del');
const path = require('path');
const globArray = [
'images/**/*'
];
const widths = [200, 400, 600, 800, 1000, 1200, 1400, 1600];
/* This helper function adds the width suffix
to the file name. */
const addSuffix = (name, w) => {
const p = path.parse(name);
p.name = `${p.name}-w`;
return path.format(p);
}
gulp.task('diff', () => {
return Promise.all([
/* First, we select all files in the destination. */
globby(globArray, { cwd: 'dist', nodir: true }),
/* In parallel, we select all files in the source
folder. Because they don't have the width suffix,
we add them for every image width after selecting. */
globby(globArray, { cwd: 'src', nodir: true })
.then(files => files
.map(el => […widths.map(w => addSuffix(el, w)])
])
/* This is the diffing process. All file names that
are in the destination directory but not in the source
directory are kept in this array. Everything else is
filtered. */
.then(paths => paths[0]
.filter(i => paths[i].indexOf(i) < 0))
/* The array now consists of files that are in "dest"
but not in "src." They are leftovers and should be
deleted. */
.then(diffs => del(diffs));
);
Со всеми изменениями в процессе сборки, изначальные два часа работы с изображениями сократились до двух или пяти минут при каждой сборке, в зависимости от количества добавляемых изображений. Добавленное время для проверки статуса файлов оказывается совсем незначительным даже при наличии десятков тысяч изображений.
Избегаем привязки к конкретным технологиям
Jekyll это удивительный инструмент, потому что в нем встроено множество возможностей, выходящих за пределы простого создания страниц HTML. Экосистема плагинов делает Jekyll не просто генератором статических сайтов, но и полноценной системой сборки. Даже базовая версия может компилировать Sass и CoffeeScript, а плагин Jekyll asset pipeline дает не только тонну возможностей по созданию изображений, но и дополнительную уверенность, так как все изображения проверяются на существование и задействованность. Это очень важно, если у вас много изображений.
Однако, все эти выгоды даются за высокую цену, мы получаем не только производительность и время сборки, но и определенный уровень привязки к технологии. Вместо того, чтобы работать в вашей системе сборки, Jekyll сам становится системой сборки. А все, чего нет в Jekyll и его плагинах, вы должны поддерживать путем самостоятельного написания кода на Ruby.
Это создавало для нас сразу несколько неудобств. Ruby не относится к удобным языкам для начинающих. Хотя многие из нашей команды могут работать с ним, некоторые из нас не могут написать и строчки без сверки со спецификацией языка. Еще хуже, что мы уходили от традиционных CMS, чтобы получить больше свободы и гибкости, а положившись полностью на Jekyll, мы обменяли один монолит на другой. Чтобы избавиться от подобной привязки к технологии, мы сделали несколько шагов.
Разделение ответственности
Во-первых, мы убрали из обязанностей Jekyll все, что не относится к генерации HTML. Мы оставили проверку существования ресурсов,однако генерация изображений и компиляция JavaScript и стилей могут полностью делаться Gulp.
Это дало нам целый список совершенно разных плюсов:
- Если мы захотим заменить Sass на что-то иное, это затронет только часть сборки, а не весь процесс генерации сайта. То же относится и к компиляции прочих ресурсов.
- Мы можем решать, стоит ли пересобирать те или иные ресурсы. Если изменился JavaScript, а стили остались прежними, то зачем их компилировать заново? Это еще немного сокращает время сборки.
- Мы даже можем убрать сам Jekyll на определенной точке, а ключевые части системы останутся нетронутыми и функционирующими.
Во-вторых, мы убрали всю пост-обработку из Jekyll. Плагин Jekyll asset pipeline позволяет создавать хэшированные URL для JavaScript, стилей и изображений. Исключение всего этого из процесса означает, что для Jekyll останется меньше работы, не соответствующей его целям. Интересно, что при переносе этого процесса с Ruby на Node.js. мы заметили улучшение производительности. Великолепный плагин gulp-rev прекрасно справляется с задачей.
const gulp = require('gulp');
const rev = require('gulp-rev');
const revReplace = require('gulp-rev-replace');
…
gulp.task('revision', () => {
return gulp.src(['./**/*.js',
'./**/*.css', './images/**/*.*'])
.pipe(rev())
.pipe(gulp.dest(based))
.pipe(rev.manifest())
.pipe(gulp.dest('.'));
});
gulp.task('rev', ['revision'], () => {
var manifest = gulp.src('rev-manifest.json');
return gulp.src(['./**/*.html'])
.pipe(revReplace({
manifest: manifest
}))
.pipe(gulp.dest(based));
});
Итак, мы разобрались, какая часть Jekyll реализует его назначение, а какая нет. Вы можете делать удивительные вещи с Jekyll и его экосистемой, но вы также не обязаны зависеть от инструментов, которые не вполне соответствуют вашим задачам.
Обязанности Jekyll были сокращены до конвертации markdown и Liquid в страницы HTML. Все остальное делается Gulp, хотя вы можете заметить некоторую непоследовательность:
- Самописные плагины для кастомных элементов сделаны на Ruby (это единственная зависимость Ruby).
- Мы по прежнему используем Liquid, достаточно экзотический шаблонизатор.
Мы также поняли, что Jekyll не должен включаться в процесс сборки. Jekyll создавался, чтобы быть процессом сборки. Jekyll открывает и анализирует каждый файл в ходе сборки. Как только вы убираете из Jekyll все, что не относится к созданию HTML, вы берете на себя многие из встроенных возможностей Jekyll вроде инкрементальной сборки.
Вуду Liquid
Несмотря на популярность Jekyll, его встроенный шаблонизатор Liquid кажется немного странным. У него есть сходство с PHP-шаблонизатором Twig и его эквивалентом в JavaScript Swig, но в нем есть и возможности, отсутствующие где-либо еще. Liquid мощный и позволяет вкладывать в шаблон большое количество логики. Это не всегда хорошо, но это не вина Liquid. В качестве примера возьмем создание “хлебных крошек” из адреса страницы исключительно силами Liquid.
{% assign coll = site.content %}
<ul class="breadcrumbs">
<li><a href="{{site.baseurl}}/">Home</a></li>
{% assign crumbs = page.url | split: '/' %}
{% for crumb in crumbs offset: 1%}
{% capture crumb_url %}{% assign crumb_limit = forloop.index | plus: 1 %}{% for crumb in crumbs limit: crumb_limit %}{{ crumb | append: '/' }}{% endfor %}{% endcapture %}
{% capture site_name %}{% for p in coll %}{% if p.url == crumb_url %}{{ p.title }}{% endif %}{% endear %}{% end capture %}
{% endunless %}
{% unless site_name == '' %}
<li>
{% unless forloop.last %}
<a href="{{ site.baseurl }}{{ crumb_url | strip_newlines }}">{{site.name}}</a>
{% else %}
<span>{{ site_name }}</span>
{% endunless %}
</li>
{% endfor %}
</ul>
Мы не будем копаться в ужасах этого кода — но простой взгляд показывает, что код, несмотря на корректную работу не отличается ясностью, которой можно ожидать от шаблонизатора. С другой стороны, чем больше возможностей и логики вы поместите в него, тем сложнее вам будет со временем понять, что он делает. Удаление этого вуду Liquid из плагинов Jekyll будет лучшей идеей:
- Liquid ограничивается только выводом контента (циклы и простые условия).
- Заранее создавайте сложные данные. Это не доступно в Jekyll изначально, нужен плагин или сгенерированные файлы YAML или JSON.
Рассмотрим генерацию “хлебных крошек” еще раз. Плагин, заполняющий аналогичные данные, должен быть более гибким и не должен опираться на магию объединения или разбития строк. В результата шаблон Liquid, работающий с готовыми данными будет более читаемым и простым для понимания:
{% if page.breadcrumbs %}
<ul class="breadcrumbs">
<li><a href="{{site.baseurl}}/">Home</a></li>
{% for item in page.breadcrumbs %}
<li>
{% unless forloop.last %}
<a href="{{item.url}}">{{item.label}}</a>
{% else %}
<span>{{item.label}}</span>
{% endunless %}
</li>
{% endfor %}
</ul>
{% endif %}
Это сохранит ваши шаблоны чистыми и аккуратными. А если вы захотите использовать вместо Liquid другой шаблонизатор (перейдя с Jekyll на что-то другое), шаблоны будет намного проще конвертировать.
Сервер: больше, чем статические сайты
Развертывание статического сайта на первый взгляд просто. У вас есть комплект готовых файлов HTML и куча ресурсов, к которым вам нужно организовать доступ из всемирной паутины. С сервисами бесплатного хостинга, хранилищами статического контента и CDN ваши возможности кажутся безграничными. Вы можете использовать даже папку в Dropbox.
Если вы делаете больше, чем просто доставляете контент — возможно, вы находитесь в процессе миграции, тогда требования к серверу будут более высокими.
Наше решение основано на nginx, который хорош в качестве сервера для статики, но также прост в настройке, когда вам нужно больше, чем просто отдать статический сайт.
Постоянная миграция от старого к новому
С двумя тысячами страниц контента, разделенных на отдельные пакеты, у нас было две стратегии на выбор:
- конвертировать весь старый контент, подождать большого релиза и с треском провалиться;
- или начать выпускать небольшие партии контента, постепенно мигрируя.
С первым вариантом конвертированный контент будет устаревать или же будет требовать вдвое больше поддержки. И мы долгое время не получим плюсов от статических сайтов после того как все сделано. Разумеется, мы выбрали второй вариант. Чтобы обеспечить свободное развертывание нового контента, созданного на новом стеке технологий без отключения доступа к не добавленным страницам из старой CMS, мы сконфигурировали сервер nginx как сквозной прокси.

Прокси сначала обращается к папке со статическими файлами. Если файл недоступен, прокси пытается взять его с сервера старой CMS. (увеличенная версия)
{kind=link}
- Идея состояла в том, чтобы любой запрос всегда шел на развернутый статический сайт и в случае наличия контента с него передавалась страница и все ее ресурсы.
- Вместо вывода ошибки 404 при недоступности страницы, nginx отправлял запрос через старую архитектуру сервера.
Это потребовало от нас запуска nginx на собственном сервере, с указывающим на него доменом, а IP старого сервера работал как вышестоящий сервер.
# An upstream server pointing to an IP address where the old
# CMS output is
upstream old-cms {
server 192.168.77.22;
}
# This server fetches all requests and fetches the static
# documents. Should a document not be available, it falls
# back to the old CMS output.
server {
listen 80;
server_name your-domain.com;
# the fallback route
location @fallback {
proxy_pass http://old-cms;
}
# Either fetch the available document or go back to the
# fallback route.
location / {
try_files $uri $uri/ @fallback;
}
}
Так как миграция продолжалась, все больше страниц переходили со старой CMS на сервер со статическим сайтом. Когда все было сделано, мы с чистой совестью отключили все связи со старым сервером и работаем только с новым.
Необходимость в динамическом контенте
Статические сайты по определению исключают динамический контент. Но даже для самых статических сайтов возникает необходимость в динамике. Много возможностей сайтов можно реализовать на основе сервисов, работающих исключительно на клиентской стороне. Комментарии в блогах добавляются за счет таких сервисов, как Facebook и Disqus. Однако все эти возможности не критичны для вашего сайта. А так как JavaScript является слабым звеном в стеке браузерных технологий и может подвести в самый неожиданный момент, будет глупо перекладывать на него ключевые функции вашего сайта.
Для таких функций нужен сервер. Например, некоторые части нашего статического сайта являются конфиденциальными и доступ к ним предоставлен только определенной группе пользователей. Чтобы получить этот доступ, пользователь должен залогиниться, используя сервис для одноразового доступа и при этом обладать необходимыми полномочиями.
Для таких случаев мы открыли дверь для небольшого приложения на Node.js используя nginx.

Перед переходом на статический сайт, прокси перенаправляет URL к приложению Node.js, скрывая возможные статические сайты. (увеличенная версия)
{kind=link}
# This upstream points to a Node.js server running locally
# on port 3000.
upstream nodejs-backend {
server 127.0.0.1:3000
}
# Later, we pointed dedicated routes to this Node.js back end
# when defining locations.
location /search/ {
proxy_pass http://nodejs-backend;
}
Это приложение обрабатывает ID сессии, вызывает сервис для одноразового входа и небольшой поиск по сайту, созданный с помощью Lunr. Здесь важно то, что мы не изменяем существующий контент, а предоставляем дополнительный контент поверх него. Если ваш контент нуждается в большем количестве динамики, генераторы статических сайтов не подходят для ваших задач.
Редактирование контента с генератором статических сайтов
Самым большим вызовом в нашем переходе к статическим сайтам была адаптация редактирования контента к новому стеку технологий. Вы должны быть твердыми как гвозди, чтобы бросить комфорт WYSIWYG-редакторов — при том, что вы знаете, как этот самый комфорт бесит разработчиков.
Чтобы взять на борт всех, даже отъявленных скептиков, мы должны были позаботиться о следующем:
- Редактирование контента на новом сайте должно ощущаться как улучшение для автора, как в плане комфорта, так и в продуктивности. Предоставление настоящего управления контентом и хороший обзор того, как это выглядит на сайте, оправдывают сложность работы с файлами и исходным кодом.
- Авторы должны увидеть плюсы ограничений в редактировании контента. Недоступность для авторов выделения текста красным цветом это облегчение для разработчиков, так как делает сайт более последовательным, но для редакторов контента это может показаться необязательным ограничением. Опять, это проблема противопоставления управления контента и создания контента. Использование возможностей по структурированию контента вместо размышлений о его внешнем виде, на самом деле снижает барьер доступа к новой системе. Если редакторам контента позволено делать намного больше, чем это нужно на странице, то они никогда не упустят использовать вещи не первоочередной важности.
И чтобы завершить описание ситуации, отмечу, что мы поддерживаем редактирование контента двумя типами пользователей: профессиональным редактором ежедневного контента и теми, кто иногда вносит свой вклад.
Профессиональный режим
Мы предоставили нашим основным редакторам два способа редактирования.
Первый способ это настройка на компьютере редактора Node.js и Ruby, быстрое введение в работу с Git и GitHub. Конечно, это не самый простой способ начать. Это действительно довольно сложно, особенно для тех, кто не знаком с этими технологиями или с разработкой программного обеспечения как таковой. Такая сложная настройка предназначена для людей, которым нужно видеть страницу полностью, как минимум, свой пакет контента.
Преимущество таких редакторов ощущается сразу при создании контента. Написание текста в markdown это необычайно быстрый процесс. А копирование и вставка блоков контента из сайта в сайт получается намного быстрее без взаимодействия с веб-интерфейсом.
Текстовый редактор типа Atom учится на всем, что вы набираете и может сам завершать ваш код — это еще один бонус к продуктивности. Контент становится кодом и добавляются все преимущества редактирования кода. После тяжелых первоначальных шагов по настройке работа по редактированию становится легкой как бриз.
Другой способ, ориентированный на небольшие исправления и обновления существующего контента — это использование веб-интерфейса GitHub.
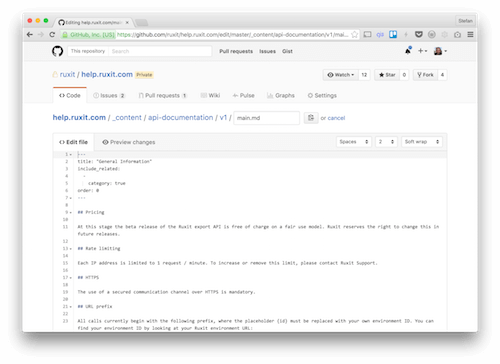
Среди возможностей GitHub есть редактирование исходников, достаточное для управления контентом в markdown, включая загрузку файлов.(увеличенная версия)
{kind=link}
GitHub хорош не только для хранения и управления исходным кодом — встроенное редактирование и загрузка файлов делают его полноценной CMS. Немного грубой, если вы хотите редактировать что-то большее, чем markdown и иметь возможность предпросмотра изображений, но все, что доступно для редактирования страниц GitHub wiki, оказалось достаточно хорошим и для нашей документации.
Одной из наибольших выгод, полученных от использования Git и GitHub в качестве хранилища данных и его пользовательского интерфейса, стала возможность работать в отдельных ветках с контентом и делать пулл-реквесты. Это было радостью при управлении контентом, так как мы могли подготовить контент пакетами, не прерывая работу сайта. Это позволило профессиональным редакторам контента заранее создать собственную версию страницы и затем отправлять ее простым нажатием кнопки “merge” на GitHub.
Доступ на GitHub однако все равно был немного ограничен. Было много помех из-за того, что он предназначен для исходного кода, а не контента и связь с реальным сайтом не предоставлена. Поэтому многие люди неспособны использовать его для создания или поддержки контента.
Облегченный режим
Для этих людей мы решили создать свой интерфейса редактирования контента, вдохновленный нашей симпатией к Ghost. Самой важной вещью для нас была возможность немедленного предпросмотра. Люди, не занимающиеся созданием контента каждый день, могут растеряться и бросить, если не видят результата того, что они набирают — особенно, когда некорректное использование кастомного плагина может повлечь ошибку при сборке.
Постоянный рендеринг контента под рукой вселяет уверенность и поддерживает работу автора контента. Было даже смешно видеть, как простые команды, трансформируются в продвинутый HTML.
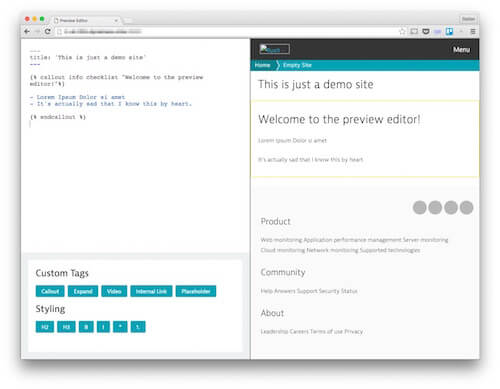
Редактор с предпросмотром контента, конвертацией markdown и большим количеством кастомных блоков для контента дает авторам хорошее ощущение результата. (увеличенная версия)
{kind=link}
При работе с интерфейсом редактирования контента мы начали переходить к полному отказу от Jekyll. Jekyll ориентирован на создание сайтов, а не отдельных страниц в одностраничном приложении. Требование ручного запуска процесса рендеринга, который был достаточно медленным, сводило на нет плюсы от непосредственности. Jekyll был неторопливо заменен на Metalsmith — фреймворк для генерации статических сайтов, обладающий одним громадным преимуществом: разнообразием выбора шаблонизаторов. Это позволило нам запускать один и тот же шаблонизатор как при сборке статического сайта, так и в нашем приложении для редакторов, сохраняя время разработчиков и делая вывод сайта и предпросмотра последовательным.
Приложение для редактирования контента не было предназначено для замены CMS. Это был способ получить легкий доступ к сложной технологии и подготовить ее для тех, кто тратит больше времени на работу с контентом.
Мы еще раз увидели улучшение продуктивности. Авторы контента обычно пишут в Word и затем вставляют текст в другие интерфейсы для редактирования контента. У этого есть побочные эффекты — это ошибки из-за копирования/вставки и дополнительные стили, которые надо удалять. Теперь же их контент был отлично подготовлен для нашего генератора статического сайта и требовал минимального внимания.
Система управления контентом на основе API
С популярностью генераторов статических сайтов мы также заметили сдвиги в стане CMS. Вместо того, чтобы быть всемогущими инструментами для всего, новое поколение CMS фокусируется на фактическом управлении контентом, опуская процесс рендеринга в пользу структурированного вывода данных через API. С нашей целью сделать управление контентом удобным для всех авторов и редакторов мы не могли пройти мимо.
Коммерческие продукты типа Contentful и их открытые альтернативы типа Cockpit дают все удобства обычных CMS, не требуя от вас особых усилий на непосредственный рендеринг контента. Традиционные CMS старой школы типа Drupal также запрыгнули на подножку с инициативами типа Headless Drupal. И даже WordPress дает вам непосредственный доступ к контенту с помощью плагина JSON API.
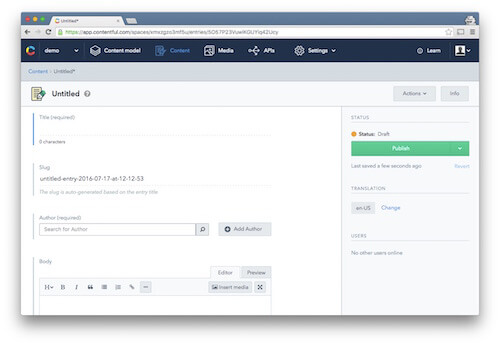
CMS на основе API, такие как Contentful обладают всеми удобствами традиционных CMS, при этом сохраняя управление и вывод контента полностью раздельными. (увеличенная версия)
{kind=link}
Если вы рассматриваете процесс генерации статического сайта как комбинацию слабосвязанных технологий, то CMS на основе API до сих пор привязаны к определенным вендорам и технологиям. Интерфейс редактирования утратил тесную связь с процессом рендеринга, однако вопрос, где и как хранить ваши данные, по-прежнему в руках CMS.
Одним из наших требований было сохранение контента в человекочитаемой и легкодоступной форме. Хранение контента в виде структурированных файлов в markdown на GitHub было ключом для быстрого движения вперед, быстрых обновлений и выбора технологий. Нам не нужен еще один процесс миграции.
Ресурсы
В нашем путешествии от простого сайта стартапа до точки, когда мы начали управлять всем контентом компании при помощи генераторов статических сайтов, мы ознакомились со множеством ресурсов.
Фил Хоуксворт неоднократно делал доклады о генераторах статических сайтов и их использовании разработчиками и дизайнерами последние два года. Его постоянно обновляемый доклад это исчерпывающий ресурс для тех, кто хочет начать работать с генераторами статических сайтов.
StackEdit это великолепный браузерный редактор markdown на основе открытого кода. В дополнение к удобному интерфейсу в нем есть возможности по интеграции с платформами хранения данных, такими как GitHub и Dropbox.
Генераторов статических сайтов просто уйма. StaticGen дает неплохой обзор и помогает вам выбрать правильный инструмент для вашей работы.
Заключение
Генераторы статических сайтов великолепны, даже когда они используются для работы, на которую изначально не ориентированы. Чтобы избежать замены одного монолита на другой, сохраняйте задачи для генератора статических сайтов ясными и поддерживаемыми. Разделение задач и взаимозаменяемость частей сборочного процесса поможет вам, если какая-либо из частей перестанет удовлетворять вашим нуждам.
В дополнение к техническим вызовам критически важным остается и человеческий фактор. Люди должны видеть преимущества работы в новом окружении. Позаботьтесь об этом и помогайте при необходимости им стать более продуктивными, чем когда-либо.